

AI Search & RAG on Your Website
If your visitors still struggle with keyword search boxes and “no results” pages, it’s time to move to AI search. Modern AI search systems use Retrieval-Augmented Generation (RAG) to fetch relevant knowledge from your own content and generate answers with citations. Done right, AI search improves self-service resolution, reduces support tickets, and boosts conversions—without retraining huge models. RAG simply adds the missing piece: retrieval of fresh, trusted content before the model answers.
What is AI search and RAG?
AI search augments traditional search with semantic understanding and generative answers. RAG is the technique of retrieving relevant documents (from your site, help center, catalog, PDFs) and passing them to the model as grounded context before it writes an answer. This improves factuality and lets the model say “I don’t know” when evidence is missing.
Why AI search beats keyword-only search
-
Semantic matching:
Finds meaning, not just exact terms. -
Grounded answers:
Cites your sources to build trust. -
Freshness:
Uses your most recent content, not last year’s training data. -
Task completion:
Generates summaries, comparisons, and step-by-steps.
For e-commerce and content sites, AI search consistently outranks pure keyword search on relevance; hybrid approaches (keyword + vector) are now mainstream.
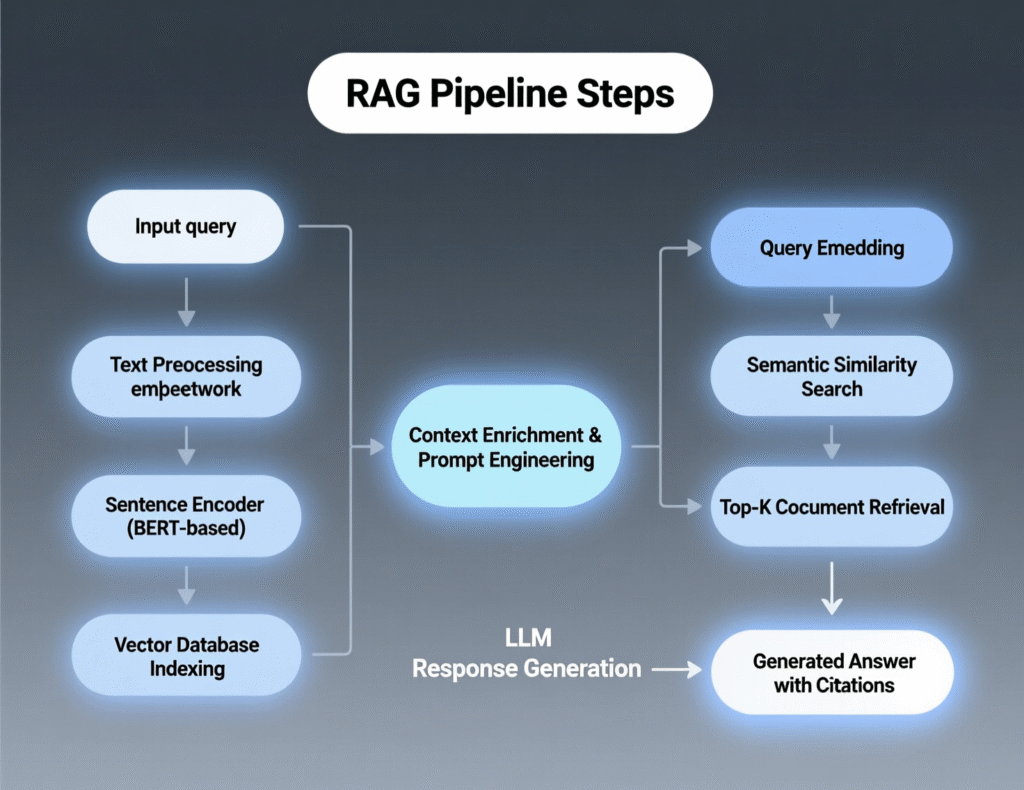
How AI search and RAG work (the pipeline)
-
Ingest & normalize:
Crawl or sync content (HTML, PDFs, knowledge base, product feed). -
Chunk & enrich:
Split into passages; add metadata (URL, product IDs, timestamps). -
Embed:
Turn text into vectors using an embedding model (e.g.,text-embedding-3-large). -
Index:
Store vectors in a vector database (e.g., Pinecone, Weaviate, Qdrant, pgvector / Elasticsearch dense_vector). -
Retrieve:
K-NN vector search; optionally hybrid (BM25 + vectors). -
Rerank:
Use a cross-encoder (e.g., Cohere Rerank 3.5) to reorder results by semantic relevance. -
Generate:
The LLM (e.g., GPT-4.1 family) composes an answer using only retrieved snippets, with citations. -
Guardrails:
Safety policies; restrict to allowed sources; handle PII. -
Evaluate:
Relevance, accuracy, latency, cost.
Retrieval options you’ll choose
-
Vector-only search:
Best for semantic queries and long-form content. -
Keyword + vector (hybrid):
Adds precision for short queries and filters (brand, SKU). -
Elasticsearch dense vectors:
Production-provendense_vectorfield with kNN/HNSW; great if you already run Elastic.
Your implementation paths
Turnkey “AI search” products (fastest path)
-
Algolia NeuralSearch hybrid keyword + vector + reranking; SDKs for web and mobile.
-
Google Vertex AI Search—Google-quality search/RAG for websites and intranets. Google Cloud
-
Amazon Kendra GenAI Index—managed retriever tightly integrated with Bedrock & Q Business.
When to pick this
you need speed to value, enterprise security, analytics, connectors, and don’t want to run vector infra.
Cloud-native RAG kits
Cloud vendors now publish end-to-end reference stacks (ingestion + embeddings + retrieval + generation + eval). For example, AWS demonstrates multimodal RAG pipelines using Bedrock and Knowledge Bases.
Build-your-own (maximum control)
-
Embeddings:
OpenAItext-embedding-3-large(high accuracy) or-3-small(budget). Official price points: ~$0.13/M tokens (large) and ~$0.02/M (small). -
Vector DB:
Pinecone (managed), Weaviate/Qdrant (open-source), pgvector/Elasticsearch (if you live in SQL/Lucene). -
Reranking:
Cohere Rerank v3.5 (cross-encoder), widely supported across clouds and marketplaces.Tip
Start hybrid (BM25 + vector). It’s usually the best baseline for AI search relevance with controllable latency.
Content prep: where AI search succeeds or fails
-
Chunk size:
200–400 tokens often balances recall and precision. -
Metadata:
Attach URL, title, section, product category, price, last-modified. -
De-duplication & canonicalization:
Avoid near-duplicate passages. -
Citations:
Store a stable anchor (URL + heading) so AI search can link back. -
Image/PDF extraction:
OCR for scans; capture alt text and figure captions.
Budget & latency math (a quick, concrete example)
Let’s say you embed 5,000 help-center pages averaging 1,200 tokens each = 6M tokens. With text-embedding-3-large at $0.13 / 1M tokens, one-time indexing ≈ $0.78. For updates, you’ll pay only for changed content. Query-time costs depend on your reranker and generator.
On the vector DB side, Pinecone’s Starter tier lets you try small apps; paid tiers charge by storage and read/write units (see live pricing for current limits).
Latency budget
Aim for P95 < 1.5s page-to-answer. Common split: retrieval 80–200ms, rerank 80–180ms, generation 400–900ms with short, cited answers.
Security, governance, and compliance
-
Scopes & ACLs:
Index only permitted documents; apply per-user filters. -
PII handling:
Redact in chunks or mask at generation time. -
Source restrictions:
Force AI search to cite only your domain. -
Auditability:
Log queries, documents retrieved, and answer trace.
Evaluation: a simple “HowTo” for improving AI search
-
Define goals:
Clicks on citations, deflection rate, conversion uplift. -
Create a test set:
100–300 real user queries with gold-standard answers. -
Offline eval:
Measure NDCG/MRR after retrieval and after rerank. -
Human review:
Ask “Is the answer correct, complete, cited?” -
A/B test in production:
Answer vs. control (existing search). -
Iterate:
Tune chunking, filters, rerank depth; add examples to prompts.
Mini-case studies (evidence)
-
Enterprise knowledge management
A retail group reported 70% faster support resolution and 45% lower knowledge-base maintenance costs after rolling out a RAG system (case study). Vendor-reported, but directionally illustrative. -
Customer support automation
AI support platform Fini cites brands automating 88% of tickets with RAG-style agentic flows. Vendor-reported; validate with a pilot before extrapolating.
Market context: why invest now
Analysts project rapid RAG growth through 2030, with multiple firms estimating multi-billion-dollar markets as AI search adoption accelerates. Meanwhile, AI-driven search spending is forecast to surge in the U.S. this cycle—an indicator that AI search is becoming a core channel.
Common pitfalls and how to fix them
-
Hallucinations:
Add stricter citations and “no-answer” fallback. -
Drift:
Re-embed only changed pages; schedule incremental crawls. -
Slow answers:
Cap retrieved chunk count; use rerank depth of 20–50. -
Thin content:
Improve docs; AI search can’t invent missing facts. -
No analytics:
Log queries and unanswered intents; turn them into new content.
Outlook
AI search with RAG is a practical, proven way to give users fast, trustworthy answers from your own content. Start with a small slice (help center, docs, top products), pick a stack (turnkey or custom), and measure real business outcomes—deflection, conversions, satisfaction. If you treat AI search like a product (not a plugin), you’ll build an unfair advantage.
CTA: Want a prioritized, 30-day rollout plan for AI search on your site (stack, costs, sample prompts)? Reach out and we’ll tailor a plan to your content and KPIs.
FAQs
Q : How does AI search differ from my current site search?
A : AI search uses semantic vectors and RAG to understand intent and answer with citations, while keyword search matches exact terms. Hybrid setups keep keyword precision while adding semantic recall and answer-generation.
Q : How do I start implementing RAG on my website?
A : Begin with ingestion, chunking, embeddings (text-embedding-3-large or -3-small), a vector DB, retrieval + rerank, and a generation step with strict citations. Pilot on one content area before scaling.
Q : How much does AI search cost?
A : Embedding is inexpensive (e.g., ~$0.13/M tokens for OpenAI large embeddings). Vector storage + read/write units and rerank/generation calls dominate ongoing costs. Start with a pilot to model true traffic.
Q : How can I reduce hallucinations?
A : Use strict retrieval-only prompting, require citations, add “no-answer” behavior, implement rerankers, and evaluate regularly with a labeled test set.
Q : How secure is AI search for private content?
A : Keep indices private, enforce ACL filters at query time, log access, and restrict the model to allowed sources. Enterprise offerings (Vertex AI Search, Kendra) provide these controls.
Q : How do I measure success?
A : Track answer clicks, citation clicks, deflection rate, conversion uplift, and qualitative accuracy ratings. Run A/B tests before full rollout.
Q : How can AI search improve support KPIs?
A : Grounded answers resolve common questions instantly. Case studies report faster resolutions and higher deflection; validate with your own pilot and metrics.
Q : How do I choose a vector database?
A : Consider hosting model (managed vs self-hosted), scale, filters, hybrid search features, budget, and your team’s ops maturity. Pinecone, Weaviate, Qdrant, Milvus, and Elastic are common picks.
Q : How can I make AI answers cite my pages?
A : Store stable URLs and headings in metadata; instruct the model to cite those sources; and evaluate citation correctness in your QA loop.