
AI Data Loss Prevention for Apps: 9 Essential Controls
AI Data Loss Prevention for Apps: 9 Essential Controls

AI Data Loss Prevention for Apps: 9 Essential Controls
AI data loss prevention is the set of policies, controls and monitoring layers that stop sensitive data flowing into or out of AI systems in unsafe ways. In practice, that means inspecting prompts, files, training pipelines and model outputs in real time, then blocking, masking or redacting risky content before it leaves your environment or reaches the wrong user.
For GenAI and LLM-based applications, the most effective AI data loss prevention programs combine identity and access control, prompt redaction, output filtering and detailed logging, applied at the browser, proxy, AI gateway and app layers. Done well, you keep customer, payment and patient data safe while still letting teams use tools like ChatGPT, Copilot and internal copilots productively across the US, UK and EU.
Introduction
Picture this: a sales rep in New York pastes a full customer export names, emails, contract values into a public AI chat tool to “clean it up for a QBR deck.” In London, a developer drops API keys and database connection strings into Copilot. In Frankfurt, an internal GenAI assistant unexpectedly surfaces training snippets that look suspiciously like real patient notes from a Berlin hospital. None of these teams think of it as a breach. Regulators will disagree.
This is exactly where AI data loss prevention comes in. It’s the bridge between “move fast with GenAI” and “don’t end up explaining an LLM data leak to the GDPR regulator, the ICO, or a US state AG.” Instead of banning AI outright, you shape where data can flow, which users can send what, and which outputs are safe to show.
In this guide we’ll walk through what AI DLP actually means, why traditional DLP is not enough, an AI-ready architecture, nine practical control patterns, governance for tools like ChatGPT and Copilot, alignment with GDPR, the EU AI Act, NIS2 and sector rules, and how to evaluate and roll out tools across US, UK, Germany and wider EU teams.
What Is AI Data Loss Prevention in Enterprise AI and LLM Applications?
AI data loss prevention is the set of policies, controls and monitoring that stop sensitive or regulated information from entering or leaving AI systems in unsafe ways. In enterprise GenAI use, that includes prompts, file uploads, chat logs, training data pipelines, vector databases and calls to external AI APIs – not just classic databases and file shares.
Unlike traditional DLP, AI DLP has to understand natural language, code and semi-structured content in real time, recognise personal data, payment data and trade secrets, and apply guardrails before information reaches external models or untrusted users. It spans custom LLM apps, internal copilots and public tools like ChatGPT, Copilot or Gemini.
Clear Definition of AI Data Loss Prevention
AI data loss prevention is a security and governance layer that inspects AI prompts, attachments, training data and model outputs, then blocks, masks or redacts sensitive content based on policy before it crosses a trust boundary. Typical scope includes.
User prompts and chat messages
File uploads and RAG documents
LLM and embedding API calls
Vector databases and retrieval indices
AI chat logs and analytics pipelines
In other words, AI DLP is how you implement AI security controls for LLM applications and reduce GenAI data exfiltration risks without killing usefulness.
Key Risks of Data Leakage in GenAI and LLM Tools
Most AI leaks don’t come from evil masterminds; they come from rushed humans:
Staff paste PII, PHI or payroll spreadsheets into prompts.
Engineers paste source code, secrets and architecture diagrams for “quick reviews.”
Analysts upload transaction exports or EMR/claims extracts to summarise.
Models can also memorise training examples and echo them back in outputs, especially when fine-tuning on small, sensitive datasets. Shadow AI personal ChatGPT accounts, unmanaged browser tools or local “AI widgets” bypasses corporate SSO and logging entirely.
A few realistic scenarios.
A US health startup in San Francisco lets clinicians experiment with an LLM note-summariser. One doctor pastes full unredacted ED notes, creating an unlogged HIPAA exposure.
A London asset manager’s analyst uses a personal AI account to summarise client pitch books that include confidential deal pipelines.
A German insurer in Berlin experiments with a claim-summarisation model. An engineer accidentally fine-tunes on raw claim PDFs; later, adjusters see snippets of other customers’ descriptions in model outputs, raising DSGVO/GDPR concerns.
AI DLP vs Traditional DLP
Traditional DLP was built for emails, web uploads and file sync tools, not for conversational AI and streaming APIs. It works best on:
Attachments and files leaving via email or FTP
Web uploads to known domains
Endpoint clipboard and file movements
But GenAI changes the data flow:
Prompts and responses are streaming text, often encrypted, inside SaaS tools.
LLM-powered copilots fetch data from CRMs, ticketing systems, EMRs and code repos at runtime.
Users interact in browsers and native apps where legacy DLP may see nothing.
Classic DLP still matters for endpoints, email and secure web gateways but you now need an AI-ready data loss prevention architecture layered closer to the AI apps, APIs and users.
Why Are Traditional Data Loss Prevention Tools Not Enough for GenAI and LLM-Based Applications?
Legacy DLP tools were designed for email, web uploads and file sharing — not for real-time LLM conversations, AI gateways or agentic workflows. They typically can’t see prompts and responses inside AI chat tools, don’t understand model context or training data, and often struggle with multilingual, unstructured text at GenAI scale.
Relying only on classic DLP leaves blind spots around browser-based AI tools, internal LLM APIs and training pipelines. GenAI requires new controls closer to the model and user, not just at the network edge.
Limitations of Legacy Network and Endpoint DLP
Most legacy DLP engines are pattern-driven: regexes for credit cards, SSNs, IBANs; keyword lists for “confidential,” “salary” or “PHI.” In an AI world, that’s not enough because:
Context-rich prompts (“Please draft a letter to this Berlin patient about their oncology results…”) are hard to classify with signatures alone.
Encrypted SaaS and proprietary AI protocols limit visibility for inline appliances.
High false positives create “click accept” fatigue users override warnings to get work done.
New Data Flows Introduced by LLMs and GenAI
A typical data path for an AI-powered app now looks like.
User → Web / mobile UI → Backend app → AI gateway → LLM / retrieval → Logs & analytics
LLM-powered copilots may pull from:
CRMs (Salesforce-style)
Ticketing tools (Jira, ServiceNow)
Code repos (GitHub, GitLab)
EMRs and HIS in health systems like the NHS
Shared drives and knowledge bases
Remote work and browser-based chat UIs mean much of this happens over HTTPS inside a browser tab, not a neatly managed “corporate app.” Legacy DLP often sees nothing.
Business Impact of AI Data Leaks
The downside is not just embarrassment.
Regulatory exposure
GDPR/DSGVO fines in the EU, UK-GDPR enforcement by the ICO in the UK, HIPAA civil penalties in US healthcare, and PCI DSS non-compliance in payments can all be triggered by AI-driven leaks.
Contractual and IP risk
NDAs, trade secrets, proprietary models and source code accidentally used to train a third-party model or exposed in outputs.
Reputational damage
A 2026 Netskope report suggests generative AI data policy violations have more than doubled year-on-year, with typical organisations seeing around 200+ AI-related data incidents per month.
No CISO wants to be in the boardroom explaining why “cut-and-paste into AI” wasn’t covered.
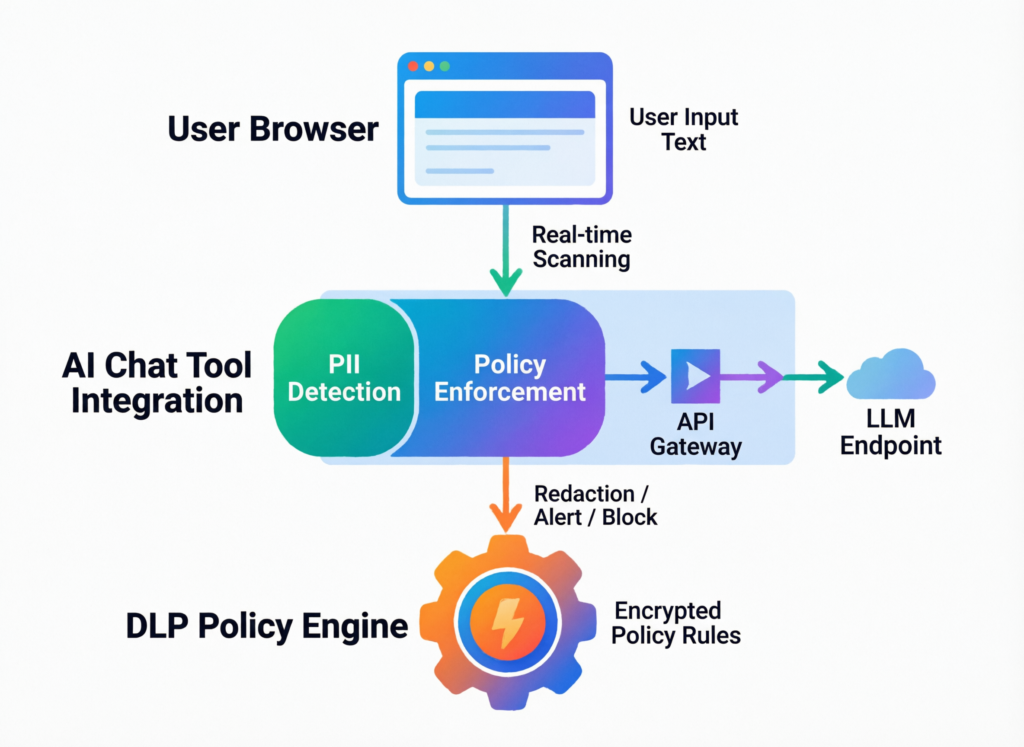
AI-Ready Data Loss Prevention Architecture for LLM and GenAI
An AI-ready DLP architecture adds semantic, AI-aware controls on top of your existing security stack instead of replacing it.
Reference Architecture for AI DLP
Think in layers
Identity & RBAC
Centralise identities and roles (IdPs, SSO) and define which roles can access which AI apps, models and data domains.
Data classification & tagging
Label PII, PHI, card data, trade secrets and “crown jewel” datasets in data lakes, CRMs and document stores.
AI gateway / proxy
Route all LLM and GenAI traffic through an AI gateway/firewall that can inspect prompts and outputs, enforce policies and choose models.
Input/output filters
Apply redaction, masking, tokenisation and safety filters on prompts and responses.
Logging & monitoring
Stream AI telemetry into SIEM, observability and business intelligence tooling for detection and audits.
You still use SIEM, CASB and traditional DLP, but GenAI-aware inspection happens at the AI gateway and browser/proxy edge. If you’re already building orchestration and dashboards around this telemetry, Mak It Solutions’ Business Intelligence Services can help you turn AI logs into clear reporting for security and compliance teams.
Mapping Controls Across the AI/LLM Lifecycle
AI DLP should cover the full lifecycle.
Training & fine-tuning
Scrub PII and secrets from training data, enforce data minimisation, and track provenance for GDPR and EU AI Act duties.
Inference
Inspect prompts and responses in real time, block risky flows, and rate-limit high-risk actions (e.g., bulk exports, code generation against production data).
Post-processing
Redact logs, implement retention limits and pseudonymise where full traceability isn’t needed.
Regional Design Considerations in the US, UK, Germany and EU
Geography shapes your architecture.
Data residency & cross-border transfers
EU workloads may require EU-only regions and careful transfers to US-based models under GDPR and the EU AI Act.
Sector rules
Healthcare (HIPAA in the US, NHS and EU hospital guidance), finance (BaFin and FCA-style supervision), and public sector each add sector-specific constraints.
NIS2 and critical services
For essential and important entities under NIS2, AI DLP should tie into incident reporting, supply-chain risk and business continuity plans.
The 9 Essential AI Data Loss Prevention Controls (At a Glance)
Before we dive into details, it helps to see the nine core control patterns you’ll rely on again and again:
Identity and RBAC
Strong identity, SSO and role-based access to AI tools and data.
Data classification and tagging
Clear labels for PII, PHI, card data, trade secrets and “crown jewels.”
Input redaction and masking
Remove or tokenise sensitive fields in prompts and file uploads.
Output filtering and review
Filter hallucinated PII, training-data echoes and disallowed content in model responses.
AI gateways and proxies
Central choke point for AI traffic with policy enforcement and model routing.
Structured logging and monitoring
Detailed AI telemetry for audits, forensics and optimisation.
Zero-retention and “no training” modes
Tight data-handling controls for external GenAI vendors.
SIEM/SOAR integration
AI DLP events feeding your wider detection and response processes.
Regional and sector safeguards
Controls tuned for GDPR, EU AI Act, NIS2, HIPAA, PCI DSS and local regulators.
The rest of this guide shows how to implement these AI data loss prevention controls in real-world GenAI apps.
Practical Controls That Best Prevent Data Leakage in AI Apps Handling Sensitive Data
The most effective AI data loss prevention programs combine identity and access control, prompt redaction, output filtering and strong monitoring. Security teams apply controls at the browser/proxy, AI gateway and application layers so sensitive customer, payment or patient data is blocked or masked before it reaches the model and risky outputs are filtered before users see or share them.
Input Controls for AI Prompts.
Start with the inputs:
Automatic redaction/masking
Use detectors to find PII/PHI, payment data and secrets in prompts and file uploads, then mask or tokenise fields before they leave the browser or app.
RBAC and attribute-based control
Only certain roles (e.g., senior clinicians or risk officers) should be allowed to send identifiable data to high-trust internal models. Others get anonymised or synthetic views.
Patterns for regulated industries
For AI data loss prevention controls for HIPAA-covered entities, restrict PHI to HIPAA-compliant internal deployments, enforce zero-retention with external vendors and log all PHI-related prompts for audits. For BaFin-regulated banks, log model calls against customers and keep data in approved regions.
How Can Security Teams Implement Prompt and Output Filtering to Stop LLM Data Leakage Without Blocking AI Adoption?
Security teams can deploy policy engines that inspect prompts and responses in real time, using rules for regulated data classes and business-defined “crown jewels.”
For prompts, the engine can block, mask or tokenise sensitive fields (emails, card numbers, MRNs) while preserving enough context to be useful. For outputs, it can filter out hallucinated PII, training data echoes and disallowed content before it reaches users, with clear messages explaining what was blocked and why. Teams usually start with high-risk groups and apps, then expand to wider staff once patterns stabilise.
Practical patterns include.
Soft block with coaching
Instead of just “Denied,” show “We removed patient identifiers from your prompt to keep this HIPAA-compliant.”
Sensitivity tiers
Allow internal HR copilots to see anonymised pay bands, while finance gets precise amounts.
Model routing
Route highly sensitive prompts to single-tenant internal models and low-risk ones to cheaper public APIs.
For more examples of guardrails around prompts and agents, you can connect this with Prompt Injection Attacks in LLMs for Secure AI Agents.
Logging, Monitoring, and Zero-Retention Policies for GenAI Vendors
You can’t defend what you can’t see.
Structured AI logs
Capture prompts, key decisions (blocked/allowed/masked), model IDs, data categories and user IDs, ideally in a central AI observability stack.
Zero-retention and “no training” modes
For external vendors, prefer configurations where prompts are not stored or used for model training. Where that’s impossible, pseudonymise and minimise.
SIEM/SOAR integration
Stream AI DLP alerts into your SIEM and automate incident response: notify data protection officers for suspected GDPR breaches, open tickets for repeated policy violations, and trend risks over time.
AI observability and AI DLP work well together; if you’re already investing in observability, use articles like AI Observability: Monitor Drift, Cost and Quality as an adjacent reference.
Governing Public AI Assistants Like ChatGPT and Copilot Without Killing Productivity
Public AI tools are often where leaks start but they’re also where users see the biggest productivity wins.
Why Do AI Chat Tools Like ChatGPT and Copilot Create New Data Leakage Risks for Organisations?
Employees can paste sensitive client, patient or source-code data straight into external AI tools that may log or train on that content. These tools often sit outside corporate SSO and network boundaries, and default settings may retain prompts and responses.
Because the models are so powerful, a single misused prompt (e.g., “Summarise these 5,000 claim files” or “Explain this production config”) can expose far more data than traditional copy/paste or email ever did.
Browser-Based and Proxy DLP for AI Chat Tools
To manage this, organisations increasingly use.
Browser extensions / agents
Inspect prompt text and file uploads in the browser; warn, block or redact before data reaches ChatGPT-style tools.
Secure AI gateways / reverse proxies
Route traffic to tools like ChatGPT or Microsoft Copilot via a corporate domain so you can log and control flows.
Policy examples
Block upload of files marked “confidential,” restrict certain domains (e.g., no client emails), and allow safe patterns (brainstorming copy, refactoring redacted code).
“Hard block everything” causes workarounds and shadow AI. “Guardrailed enablement” safe defaults plus visible controls is usually more realistic.
Practical Policies for Staff Use in US, UK and EU Organisations
Keep policies simple and role-based.
Who can use which tools (e.g., engineers can use Copilot, but legal must use an internal assistant).
What data is allowed (no live customer lists, no patient identifiers, no card numbers).
Where it’s stored (prefer enterprise licences with admin controls, logs and region choices).
Localise examples: HIPAA-covered PHI in US health systems, UK public-sector data, and GDPR-protected personal data in Germany, France, Netherlands, Spain and Nordic markets. Tie staff training to concrete stories, not abstract law, and reuse explainers from pieces like Enterprise AI Agents for US, UK & EU: A Practical Guide.
Designing AI DLP Controls to Align With GDPR, the EU AI Act, NIS2 and Sector Rules
How Should Companies in Europe Design AI DLP Controls to Align With GDPR and the EU AI Act?
Start with data protection by design and by default: classify personal and special-category data, and enforce minimisation and purpose limitation across AI workflows. GDPR already expects this; the EU AI Act will add explicit obligations for high-risk AI systems around data governance, logging, risk management and human oversight.
AI DLP can enforce these principles technically:
Block prohibited data uses (e.g., no biometric data in certain contexts).
Enforce consent/legal-basis rules for training and inference.
Provide evidence for DPIAs via AI logs, risk assessments and incident records.

Integrating AI DLP With NIS2 Cybersecurity Measures
NIS2 requires a “high common level of cybersecurity” for essential and important entities, including risk management, incident reporting and supply-chain security. (EUR-Lex)
AI DLP supports this by.
Treating AI services and LLM gateways as critical assets.
Integrating AI leak alerts into incident-response playbooks.
Assessing third-party AI vendors (including GenAI APIs) under the same vendor risk programme as other cloud services.
Sector Examples: Health, Finance and Public Sector in Europe and the US
Healthcare
For clinical decision-support tools in US hospitals or NHS providers, use AI DLP to block raw identifiers in prompts, maintain PHI access logs and keep inference within HIPAA-aligned and UK/EU-compliant regions. (HHS.gov)
Financial services
In BaFin-regulated banks in Frankfurt or Berlin, align AI DLP with ICT and cloud outsourcing guidance: clear inventories of AI systems, data residency controls and detailed logs for credit and trading use cases.
Public sector
For GenAI use in casework, benefits and tax workflows, enforce strict logging, human-in-the-loop review and transparency about how AI is used in decision-making.
Evaluating and Rolling Out AI Data Loss Prevention Tools and Policies
Evaluating AI DLP Tools and Platforms
When comparing platforms (from GenAI-native DLP like Lakera or Nightfall-type tools through to broader suites), focus less on branding and more on capabilities:
Coverage of browser-based tools, internal LLM APIs and SaaS apps.
Detection quality on natural language, code and multilingual content.
Latency impact on user experience.
Privacy posture (on-prem, VPC, data residency) and certifications.
Integrations with your SIEM, CASB, IDP and ticketing stack.
Make sure AI-aware DLP complements, not replaces, your classic DLP and email/web security.
Integrating Microsoft Purview and Existing DLP With AI Use Cases
If you’re Microsoft-centric, you probably already use Microsoft Purview DLP and sensitivity labels. Extend that investment by.
Applying unified labels to M365 data that Copilot can access.
Using Purview’s DLP policies to monitor Copilot interactions with SharePoint/OneDrive.
Avoiding policy silos: treat “AI rules” as another surface for existing information-protection policies, not a separate universe.
Similar logic applies if you use Google Workspace, Salesforce Shield or other DLP-like stacks.
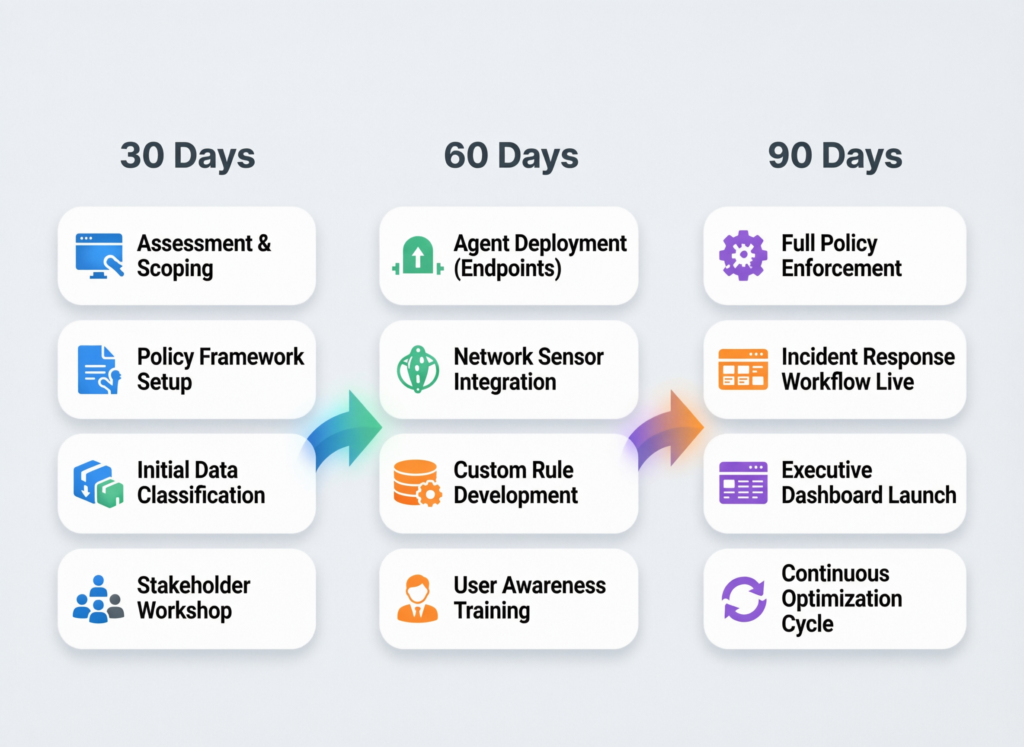
AI DLP Rollout Roadmap, KPIs and Change Management
Think in 30/60/90 days:
Days 0–30 – Discovery
Map AI usage (sanctioned and shadow), critical data flows and high-risk personas. Quick wins: enable enterprise licences for key tools, disable personal accounts and pilot browser-based controls in one team.
Days 31–60 – Pilot & design
Pilot an AI gateway/DLP stack on 1–2 critical apps (e.g., internal support copilot, developer Copilot for New York and London teams). Tune detection, coach users and agree on standard policies.
Days 61–90 – Expansion & hardening
Roll out to more teams and regions (e.g., US, UK, Germany/EU), refine KPIs, and integrate with incidents and governance boards.
Track KPIs such as blocked incidents, coverage of high-risk apps, false positive rate, AI adoption metrics and “time to approve” for exceptions. For deeper operating-model ideas, it’s worth revisiting Human-in-the-Loop AI Workflows That Actually Scale alongside this AI DLP roadmap.
Key Takeaways
AI DLP is broader than classic DLP
It covers prompts, outputs, training data and AI APIs, not just files and email.
Legacy DLP has major blind spots for GenAI
You need AI-aware controls at the browser, proxy, AI gateway and app layers.
Nine core control patterns matter most
Identity/RBAC, data classification, input redaction, output filtering, AI gateways, logging, zero-retention modes, SIEM integration and regional safeguards.
Compliance is design, not paperwork
Align AI DLP with GDPR, EU AI Act, NIS2, HIPAA, PCI DSS and BaFin/sector rules from day one, especially in high-risk health and finance workflows.
Rollout is an organisational change, not just a tool
Start with discovery and pilots, then scale with clear KPIs, training and governance boards.
If you’d like help designing AI data loss prevention for your GenAI roadmap, Mak It Solutions can work with your security and product teams to blueprint an AI-ready DLP architecture from browser controls to AI gateways and observability. We’ve already published deep dives on AI agents, observability and prompt security, and can turn those patterns into a practical implementation plan for your US, UK, Germany and EU teams.
Reach out via the Mak It Solutions website to request an AI DLP architecture review or a scoped implementation estimate tailored to your sector and risk profile.( Click Here’s )
FAQs
Q : What types of data should be in scope for an AI DLP program?
A : An AI DLP program should cover any data that could cause harm if leaked or misused by an AI system. That always includes personal data (names, emails, IDs), special-category data under GDPR (health, biometrics, beliefs), PHI under HIPAA, payment card data under PCI DSS, credentials and secrets, source code and trade secrets. In heavily regulated sectors, add internal policy documents, supervisory correspondence and sensitive model artefacts like risk models or pricing logic. It’s better to start with a broader scope and refine than to discover “blind spots” via an incident.
Q : How can mid-sized companies budget for AI data loss prevention without replacing their existing DLP stack?
A : Most mid-sized teams don’t need to rip and replace. Start by extending what you already own: use existing DLP or CASB licences, add AI-aware browser controls and configure AI-safe policies in collaboration suites like M365. Then, for the most critical AI apps, pilot a focused AI gateway or LLM firewall rather than a full platform replacement. Bundling AI DLP into broader security or cloud budgets and tying it to concrete AI projects (e.g., a Copilot rollout or customer-support copilot) helps justify spend instead of treating it as a standalone “nice to have.”
Q : Can cloud provider security tools alone protect against GenAI and LLM data leakage?
A : Cloud-native controls from providers like AWS, Azure and GCP are powerful, but they weren’t designed as complete AI DLP solutions. They help with network segmentation, encryption, key management, IAM and logging at the infrastructure layer. However, they typically don’t inspect prompts in SaaS tools, enforce fine-grained masking on LLM outputs or cover shadow AI use from unmanaged devices. You’ll usually combine cloud controls with AI-aware DLP at the browser or proxy, plus an AI gateway for prompts/outputs, to get full coverage across SaaS, internal apps and external APIs.
Q : What’s the best way to start discovering unsanctioned AI apps and shadow AI use in my organisation?
A : Start with telemetry you already have: CASB logs, secure web gateway reports, endpoint EDR and DNS logs. Look for traffic to popular AI domains (ChatGPT-style, Copilot, Gemini, Claude, etc.), then group by department and geography. From there, talk to those teams to understand actual use cases before you rush to block anything. Many organisations also run short staff surveys or internal campaigns (“Tell us where you already use AI at work”) to surface shadow AI. Once you understand the landscape, you can replace risky shadow tools with sanctioned, logged alternatives and roll out browser-based DLP for high-risk roles.
Q : How often should AI DLP policies and risk assessments be reviewed as AI tools evolve?
A : AI usage, regulations and vendor capabilities are changing fast, so AI DLP cannot be a “set and forget” project. At minimum, review key AI DLP policies and risk assessments annually but for fast-moving organisations, quarterly reviews with a cross-functional AI governance group work better. Trigger ad hoc reviews when you add new AI vendors, launch high-risk use cases (for example, underwriting, clinical decision support or core banking processes) or when major regulations like the EU AI Act move into new phases. Keep metrics on incidents, exceptions and user feedback to drive policy adjustments over time.
[…] wider European Union have reached the same conclusion: you can’t scale digital products, media or AI without a way to prove which content is real. Deepfakes, AI voice cloning and one-click image […]