
Cloud Repatriation in 2025: Smarter Than Cloud-First?
Cloud Repatriation in 2025: Smarter Than Cloud-First?

Cloud Repatriation: When Moving Off the Cloud Pays
Cloud repatriation is the process of moving selected workloads or data from public cloud platforms back to on-premises, private cloud or colocation environments. It makes sense when sustained cloud costs (including egress and over-provisioning), latency or compliance risks outweigh the benefits of staying cloud-first, and when you can model a clear TCO and risk advantage for specific workloads rather than your entire estate.
Introduction
Public cloud is still growing fast, but cloud repatriation has quietly moved onto CIO, CTO and CFO agendas in the US, UK, Germany and across the EU. Gartner now expects public cloud end-user spending to approach roughly $700–$725 billion in 2025, yet also predicts that the vast majority of enterprises will adopt some form of hybrid cloud through 2027. At the same time, recent surveys show most organizations are not “leaving the cloud”, but are selectively bringing high-cost or high-risk workloads back on-prem or into colocation.
For executive teams in New York, London, Frankfurt or Amsterdam, the question is no longer “cloud-first or not?” but “for which workloads is public cloud still the right fit?” This guide walks leadership teams through reverse cloud migration, from the business case and compliance drivers to workload selection and cloud exit strategy design.
From “Cloud-First” to “Right-Fit Cloud”
“Cloud-first” made sense when speed and elasticity were the overriding priorities and pricing was relatively simple. Today, CIOs are recalibrating to a “right-fit cloud” mindset: use AWS, Azure, Google Cloud, Oracle Cloud or DigitalOcean where they deliver clear business and architectural benefits and use on-prem, private cloud or colocation where economics, latency or regulation demand it.
In this model, cloud repatriation, data repatriation and application modernisation on-prem are just tools in a broader multi-cloud and hybrid strategy, not a religious reversal.
CIO, CTO, CFO and Heads of Infra
This guide is written for:
CIOs and CTOs under pressure to optimize cloud spend and reduce vendor lock-in
CFOs and finance controllers challenged by unpredictable cloud bills
Heads of Infrastructure, Cloud and Platforms responsible for Kubernetes, VMware, OpenShift and bare-metal estates
Risk, compliance and data protection officers navigating HIPAA, PCI DSS, UK-GDPR, GDPR/DSGVO and sector rules
We’ll keep the language business-friendly, but detailed enough that your cloud architects and FinOps teams can work from it.
When Cloud Repatriation Makes Sense
Cloud repatriation usually makes sense when a small number of workloads drive a large share of cloud spend, especially where egress-heavy analytics, 24/7 steady-state compute or very latency-sensitive applications are involved. It becomes even more compelling where data residency and sovereignty requirements (for example under GDPR/DSGVO, UK-GDPR, BaFin or HIPAA) are easier to meet in a specific data center or sovereign cloud. If you can demonstrate lower five-year TCO, acceptable migration risk and improved negotiation leverage with hyperscalers, repatriation for those workloads is worth serious consideration.
What Is Cloud Repatriation and How Is It Different from Cloud-First?
Clear Definition of Cloud Repatriation / Reverse Cloud Migration
Cloud repatriation, sometimes called reverse cloud migration, is the process of moving workloads or data from public cloud platforms back to on-premises infrastructure, private cloud or colocation facilities. Rather than abandoning cloud altogether, most organizations repatriate specific components such as production databases, high-volume analytics clusters or latency-sensitive services while keeping other workloads on AWS, Azure, Google Cloud or Oracle Cloud.
Cloud Repatriation vs Cloud-First vs Hybrid Cloud
A cloud-first strategy assumes that new workloads should default to public cloud unless there’s a strong reason not to. It favors managed services, rapid deployment and global reach.
By contrast, a cloud repatriation strategy is reactive and selective: you identify workloads where cloud lock-in, egress costs or performance issues have eroded the original business case, and you move those pieces to on-prem, private cloud or colocated bare-metal.
Most mature teams end up with hybrid cloud:
Some workloads remain cloud-native (Kubernetes on managed services, SaaS platforms, analytics sandboxes).
Other workloads run on-prem or in colocation (for example, VMware clusters in Ashburn, Dallas, London or Frankfurt).
Network, identity and observability span both worlds.
Hybrid cloud doesn’t conflict with cloud-first or repatriation it’s the architecture that lets you apply right-fit cloud choices over time.
Data Repatriation, Data Gravity and Cloud Lock-In
To keep conversations with your board and auditors clear, it helps to align on a few terms:
Data repatriation
Moving datasets (for example customer PII, healthcare records or payment transactions) from public cloud storage back to on-prem, sovereign cloud or EU-based regions.
Data gravity
The tendency for applications, analytics and services to move closer to where large datasets live, because moving the data is more expensive than moving the compute.
Cloud lock-in
Dependency on one hyperscaler’s proprietary services, pricing and regions (including egress costs) that makes switching providers or moving workloads out prohibitively expensive or risky.
AWS, Microsoft Azure, Google Cloud and Oracle Cloud all have slightly different pricing, egress fee structures and native services which means lock-in risk and exit paths will look different for each.
Why Enterprises in the US, UK and Europe Are Moving Off the Cloud
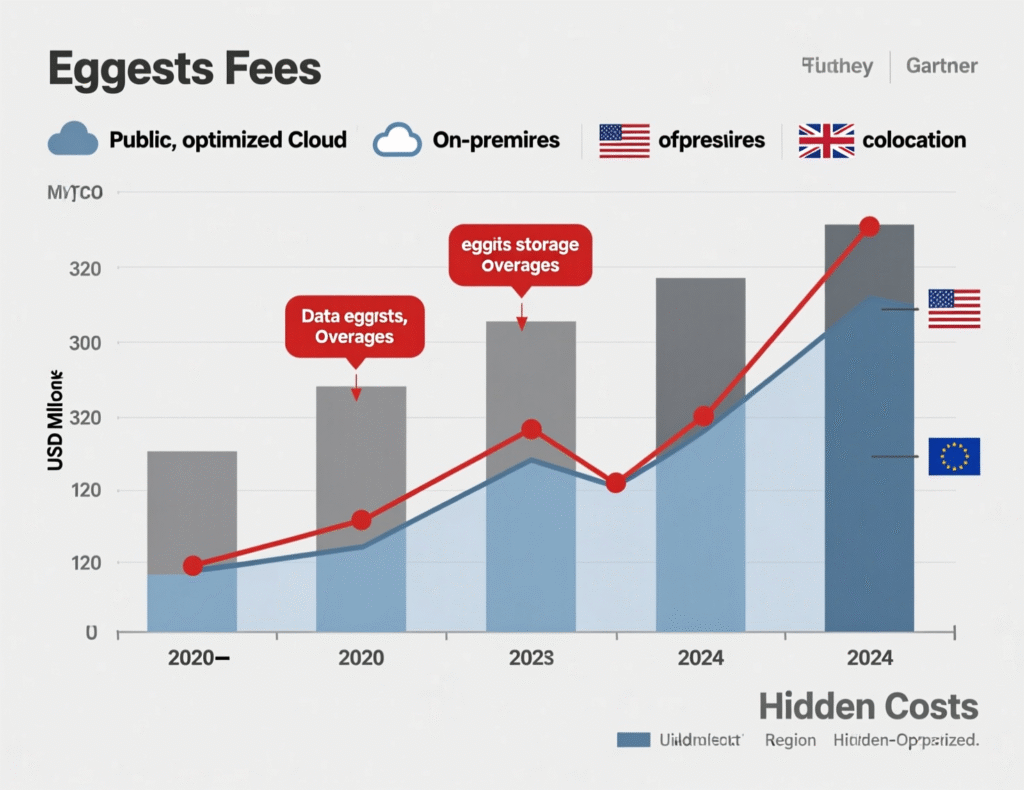
Egress Fees, Over-Provisioning and Hidden Cloud Spend
The most misunderstood costs when comparing cloud-first vs cloud repatriation are egress fees, persistent over-provisioning and unmanaged SaaS/platform consumption. Many TCO models only compare on-demand compute and storage rates, ignoring data transfer out of the cloud, managed service markups, and the operational effort to manage complex cloud estates. In some analytics scenarios, industry practitioners report that egress charges alone can approach one-third of the total cloud service bill if architectures are naive.
Typical problem patterns
Egress-heavy analytics
BI teams in New York or London pulling large data sets out of cloud data warehouses into local tools, paying per-GB transfer.
Always-on capacity
24/7 production clusters sized for peak load, rather than using autoscaling, leading to “VM sprawl”.
Untracked managed services
Search, queues, streaming, observability and backup services across multiple regions and accounts with little FinOps discipline.
Cloud spend optimization (rightsizing, reserved instances, autoscaling, better storage tiers) can fix much of this. But when optimized bills are still high versus a modern on-prem or colocation design, repatriation becomes a legitimate cost strategy especially for US SaaS platforms and EU analytics providers with stable, predictable workloads. For more on immediate optimization levers, your team can cross-check with Mak It Solutions’ own cloud cost optimization guidance. makitsol.com
When On-Prem or Colo Wins
Latency-sensitive workloads often suffer when deployed in distant public cloud regions instead of local data centers. In capital markets, for example, trading platforms in New York or London can require sub-millisecond to low-millisecond round-trip times to local exchanges; industry surveys suggest that nearly nine in ten leaders view sub-10 ms latency as business-critical for key applications.
Common candidates for reverse cloud migration include:
Market data and trading systems in New York, London or Frankfurt that are still tied to exchange colocation centers.
Real-time industrial control systems in German manufacturing hubs such as Munich or Berlin.
Edge-heavy use cases in Amsterdam or Dublin (for example IoT gateways or low-latency API hubs) that need to sit close to users or devices.
Here, colocation (for example in Ashburn, Dallas, Frankfurt or Amsterdam) with direct connectivity back to cloud can provide the right mix of performance, control and cost.
Risk, Resilience and Vendor Lock-In
Recent high-profile hyperscaler outages have reminded boards that public cloud does not magically eliminate downtime or vendor risk. At the same time, many US, UK and EU enterprises have inadvertently concentrated critical workloads (and their DR/backup) in a single hyperscaler, region or availability zone.
Repatriation discussions are often triggered by.
Single-vendor dependency
All core systems running on one hyperscaler, with limited multi-cloud or on-prem fallback.
Limited negotiation leverage
Renewals where discounts depend on committing more workloads to a single provider.
Regulatory scrutiny
European banking and payments regulators increasingly warning about systemic cloud concentration risk.
A balanced multi-cloud or hybrid strategy supported by a realistic cloud exit option gives CIOs and risk committees better leverage in negotiations and a credible story for regulators, SOC 2 auditors and internal audit.
Cloud Repatriation Strategy & Economics
Where Cloud Repatriation Actually Saves Money
Cloud repatriation saves money only where the five-year TCO beats a well-optimized cloud design, including the cost of migration and ongoing operations. That means modeling:
Steady-state infrastructure and software costs for on-prem/colo (servers, storage, networking, colocation fees in Ashburn, Dallas, London, Frankfurt).
Cloud alternatives using reserved capacity, savings plans and efficient storage classes.
Egress and inter-region transfer for analytics, backup and DR traffic.
Independent market data suggests cloud infrastructure services revenue reached around $330 billion in 2024, growing by roughly $60 billion year-on-year, driven heavily by GenAI and modernization. That growth hides a lot of inefficient spend but also shows that cloud providers will keep innovating.
Repatriation is most compelling when:
You can consolidate high-utilization workloads on modern on-prem or colocation hardware.
Workloads have predictable, non-spiky usage patterns.
You can share platforms across multiple business units (for example a shared Kubernetes or VMware platform in Frankfurt for several German Mittelstand subsidiaries).
From Cloud Spend Optimization to Repatriated Workloads
CFOs will not sign off a reverse cloud migration without a clear ROI story. A workable approach:
Cloud spend optimization first
Treat this as the baseline transformation. US SaaS providers in San Francisco or Austin can often reduce 20–30% of waste with rightsizing and architectural tweaks.
Workload-level TCO
For each candidate (for example a payments API cluster, or an NHS analytics platform in the UK), build a 3–5 year TCO comparison across cloud, on-prem and colocation.
Scenario modeling
Model best-case, realistic and worst-case migration paths, including downtime risk and dual-run costs.
Examples
A US SaaS vendor running a multi-tenant CRM platform finds that a subset of always-on microservices and databases in a single US region consumes 40% of their cloud bill; moving that footprint onto reserved bare-metal in an Ashburn colocation facility, with Kubernetes and direct cloud interconnects, delivers a 25–30% TCO reduction over five years.
A UK mid-market firm in Manchester discovers that egress for BI tools pulling from cloud data warehouses into local desktops is a major cost; repatriating the primary warehouse to a UK data center while keeping burst analytics in cloud regions like London or Dublin reduces transfer charges and simplifies UK-GDPR compliance.
A German Mittelstand manufacturer with plants in Munich and Berlin moves latency-sensitive MES and OT systems to local data centers while keeping AI analytics in EU cloud regions, satisfying BaFin-driven banking partners and KRITIS guidance.
Cloud Repatriation Risks and Challenges to Budget For
Cloud repatriation is not a free lunch. You must explicitly budget for:
Migration risk
Data transfer, cutover complexity, integration with cloud-native services and the risk of extended dual-running.
Skills and tooling
Re-building on-prem skills (Linux, storage, networking, VMware, Kubernetes) that may have atrophied in cloud-only teams.
Change management
Retraining developers used to fully managed cloud services; updating runbooks, incident response and monitoring.
In some cases, the analysis will show that staying cloud-first is better especially for highly elastic workloads, global SaaS platforms or where your team lacks the operational depth to run complex on-prem or colocation environments well.
Cloud-First vs Hybrid vs On-Prem vs Colocation
When You Should Not Repatriate
There are many cases where you should not move off the cloud at least not yet. If you haven’t done serious cloud spend optimization (rightsizing instances, turning off idle resources, using spot and reserved capacity, consolidating managed services), you will likely compare an optimized on-prem design with an unoptimized cloud footprint.
Good reasons to stay cloud-first include
Highly spiky or unpredictable workloads (for example, consumer apps, marketing campaigns, seasonal retail).
Heavy use of native managed services (for example BigQuery, DynamoDB, Azure Cosmos DB) that would be expensive to replicate on-prem.
Global customer bases where you rely on cloud regions in the US, UK and EU to minimize latency and data protection risk simultaneously.
If you’re in this camp, Mak It Solutions’ content on future of cloud hosting and multi-cloud strategy can help you design a robust cloud-first architecture, with a credible path to hybrid later. makitsol.com+1
Middle Ground for Regulated and Latency-Sensitive Workloads
Most regulated or latency-sensitive organizations land on some form of hybrid cloud or colocation
Core systems (for example payment gateways, trading engines, healthcare EHR platforms) on Kubernetes or VMware in on-prem or colocation data centers in Dublin, Paris, Amsterdam, Zurich, Frankfurt or London.
Elastic services and analytics in AWS, Azure or Google Cloud regions close to their users.
Shared services (identity, CI/CD, observability) spanning both.
European colocation providers in Frankfurt, Amsterdam, Paris and Zurich now market “sovereign cloud” options that combine physical data residency with strict operational controls, supporting GDPR/DSGVO and Schrems II requirements for EU-based hosting. makitsol.com+2EUR-Lex+2
This is also where application modernisation on-prem comes in: instead of lifting-and-shifting VMs back from cloud, many teams modernise into Kubernetes, OpenShift or bare-metal platforms located in regional colo sites, while still integrating with cloud-native services over private links.
When to Move Off the Cloud vs Stay Cloud-First
A practical way to answer “when should we move off the cloud?” is to score each major workload across 3–5 dimensions, for example (1–5 scale, higher = stronger case for repatriation)
Cost delta
After optimization, is on-prem/colo TCO significantly lower?
Latency / performance
Are there hard latency requirements (for example sub-10 ms) that the cloud cannot reliably meet?
Regulatory / data residency pressure
Would on-prem, sovereign or EU-only regions materially reduce compliance exposure?
Vendor lock-in risk
Is the workload deeply tied to proprietary services that reduce negotiation leverage?
Operational readiness
Do you have (or can you buy) the skills and tooling to run it securely off-cloud?
Workloads with high scores on cost, latency and compliance and acceptable scores for operational readiness are your prime repatriation candidates. Everything else should stay cloud-first or hybrid for now.
When Regulations Push Repatriation
HIPAA, PCI DSS, SOC 2, SOX, FFIEC and State Privacy Laws
In the US, cloud repatriation often intersects with HIPAA, PCI DSS, SOC 2, SOX, FFIEC guidance and state privacy laws like CCPA/CPRA. HIPAA’s Privacy and Security Rules, overseen by HHS, set strict requirements for protecting electronic health information that US healthcare systems in New York or San Francisco must meet, regardless of whether environments are on-prem or cloud.
Common repatriation drivers include
Healthcare providers deciding to keep EHR databases on-prem while using cloud for analytics and patient-facing apps.
Fintechs and payments providers subject to PCI DSS choosing colocation in Ashburn or Dallas with direct cloud interconnects to simplify audit scopes.
US banks responding to FFIEC and internal audit concerns about single-cloud concentration risk.
The goal is rarely “no cloud” it’s about drawing clearer compliance boundaries around data residency, logging, access control and vendor accountability.
UK-GDPR, NHS Data Security and FCA Rules
In the UK, UK-GDPR and the Data Protection Act 2018, along with NHS and FCA guidance, set the tone. The ICO hosts detailed guidance on UK-GDPR, and NHS Digital/NHSX have their own data security and protection toolkits that cloud and on-prem deployments must satisfy.
Typical patterns
NHS trusts keeping core clinical systems in UK-based data centers or sovereign cloud, while using Azure or AWS London regions for analytics and telehealth components.
London fintech startups using cloud-first architectures but repatriating core ledger or payments data to UK colocation for FCA comfort.
Open Banking platforms ensuring that sensitive APIs and data stores reside in tightly controlled UK environments, even if other services run multi-region.
Here, cloud repatriation is often about demonstrable control rather than pure cost especially when interacting with NHS, FCA or SOC 2 auditors.
DSGVO, BaFin, KRITIS and Schrems II
German and EU-wide regulations add a strong data sovereignty dimension. The GDPR (DSGVO) sets EU-wide rules, while sector regulators like BaFin and KRITIS frameworks impose additional obligations on banks, insurers and critical infrastructure operators.
Key repatriation scenarios
BaFin-regulated institutions in Frankfurt or Berlin moving core banking platforms to German data centers or EU sovereign cloud, with clear limits on data transfers outside the EU.
Critical infrastructure operators in Germany and across Europe keeping operational technology (OT) and SCADA workloads close to their facilities, while using cloud for analytics and reporting.
Organizations reassessing US cloud regions in light of Schrems II and ongoing EU-US data transfer debates, choosing EU-only hosting for some workloads.
Cloud repatriation here is often framed as data localisation and sovereignty, not anti-cloud sentiment.
Selecting Workloads and Designing a Cloud Exit Strategy
How to Identify Good Candidates for Cloud Repatriation
Good candidates for cloud repatriation share a few traits: they are expensive, predictable, critical and constrained by latency or regulation. A practical screening method:
Spend concentration
Target workloads that account for a disproportionate share of cloud costs (for example >10–15% of monthly spend each)
Egress-heavy analytics
Data warehouses and data lakes exporting large volumes to external tools or regions.
Latency-sensitive apps
Trading, IoT or real-time control systems in New York, London, Frankfurt, Amsterdam or Munich.
Data residency and sovereignty
Workloads processing regulated health, financial or critical infrastructure data under HIPAA, PCI DSS, GDPR/DSGVO, UK-GDPR, BaFin or KRITIS.
Business criticality
High business impact if unavailable, making them worth the effort of careful modernization.
Overlay this with a data repatriation strategy: where should your most sensitive data sets live (on-prem, sovereign cloud, specific EU regions), and which applications need to follow that gravity?
How to Plan a Cloud Exit Strategy Without Disrupting Services
You can plan a cloud exit strategy without disrupting critical services by treating repatriation as a phased, reversible program rather than a one-time “big bang”. Start with discovery and TCO modeling, then run low-risk pilots, and always keep a rollback and DR path.
A pragmatic exit playbook across US, UK and EU region
Discovery and mapping
Inventory workloads, data flows, compliance requirements and dependencies (including SaaS platforms, payments and healthcare integrations).
Candidate selection and TCO
Apply the scoring model above; build per-workload TCO for on-prem, colo and hybrid options.
Architecture and pilots
Design target architectures (for example Kubernetes on-prem with direct connects to AWS or Azure) and run pilots in one region (Ashburn, London or Frankfurt).
Phased migration with DR
Migrate non-critical components first, maintain DR paths in cloud, and cut over during well-planned maintenance windows.
Validation and optimization
Measure performance, cost and control; tune capacity, automation and observability before scaling to additional workloads or regions.
Where possible, reuse your existing landing zone patterns and IaC (Terraform, Pulumi, Ansible) so teams see repatriation as another environment, not a completely new world.
Negotiating with Hyperscalers and Partners Before You Repatriate
A well-designed cloud exit strategy actually improves your negotiating power with AWS, Azure, Google Cloud or Oracle Cloud. Before you start moving workloads, you should:
Review contracts and exit clauses
Understand data portability commitments, egress fee waivers, and what happens at the end of term.
Align renewal timing
Time major repatriation phases to coincide with contract renewals for maximum leverage.
Run competitive benchmarks
Use real quotes from colocation providers in Ashburn, London, Frankfurt or Amsterdam, plus on-prem hardware, to inform negotiations.
Bring partners to the table
Involve managed service providers and platform partners early so they can support hybrid designs rather than only cloud-first.
Framing repatriation as “right-sizing our cloud footprint” rather than “leaving” tends to produce better commercial outcomes and keeps relationships with hyperscalers constructive.
From Reverse Cloud Migration Strategy to Execution
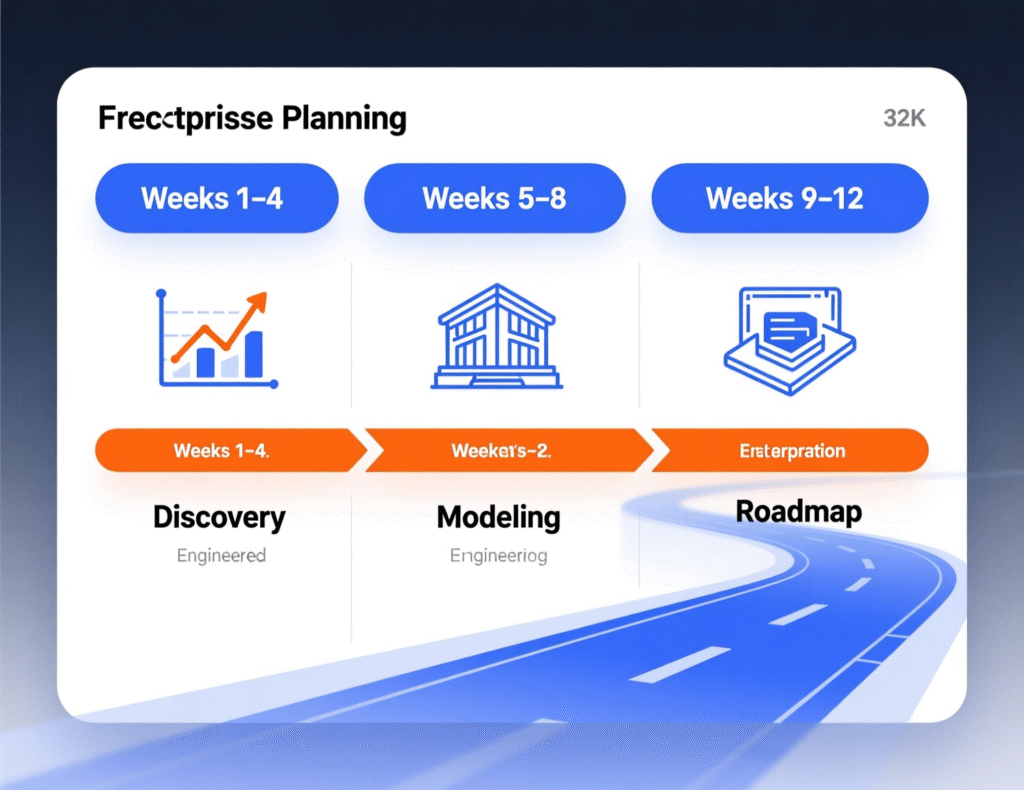
90-Day Assessment Plan for US, UK and EU Enterprises
A realistic 90-day plan for CIO/CTO teams in the US, UK and EU might look like:
Weeks 1–4
Discovery Map workloads, dependencies, compliance scope (HIPAA, PCI DSS, GDPR/DSGVO, UK-GDPR) and current cloud spend patterns.
Weeks 5–8
Modeling Build TCO models for top candidate workloads, including on-prem, colocation and hybrid options in Ashburn, Dallas, London, Frankfurt or Amsterdam.
Weeks 9–12
Options and roadmap Shortlist 2–3 target architectures, design pilots, and create a 12–24 month roadmap for reverse cloud migration where justified.
Mak It Solutions already supports similar assessments for multi-cloud and data localization projects for example in their work on GCC data localization and multi-cloud strategy and can adapt those playbooks for US, UK and EU enterprises. makitsol.com+1
What to Ask Potential On-Prem, Colo and Sovereign Cloud Providers
When evaluating on-prem, colocation and sovereign cloud providers, your RFPs should go beyond price and power:
Locations and connectivity
Exact facilities (Ashburn, London, Frankfurt, Amsterdam), available cloud on-ramps and carrier diversity.
SLAs and resilience
Uptime targets, redundancy, incident processes and regulatory assurances.
Platform support
Native support for Kubernetes, OpenShift, VMware, bare-metal automation and observability tooling.
Compliance posture
Evidence for ISO 27001, SOC 2, PCI DSS, and alignment with GDPR/DSGVO, UK-GDPR, HIPAA and sector frameworks.
Operational model
How much is fully managed vs customer-managed, and how this fits your internal skills and budget.
How Our Team Can Help Design Your Cloud Repatriation Roadmap
The Mak It Solutions Editorial Analytics Team works with cloud architects and leadership teams to turn high-level repatriation talk into concrete roadmaps. In practice, that often means:
A strategy workshop to clarify goals, constraints and regulator expectations.
ROI and TCO modeling for candidate workloads, including cloud spend optimization vs repatriation scenarios.
A proof-of-concept migration (for example one analytics cluster or transactional database) to validate performance, cost and compliance before scaling.
Alongside this, Mak It Solutions can plug in their broader expertise in cloud cost optimization, data analytics/BI and modern web and app development to ensure your hybrid architecture supports real product roadmaps not just infrastructure diagrams. makitsol.com+3makitsol.com+3makitsol.com+3
Key Takeaways
Cloud repatriation is a selective, workload-by-workload decision, not an ideological move away from cloud.
The strongest cases combine high, predictable cloud spend, strict latency or sovereignty requirements, and clear five-year TCO advantages.
Hybrid cloud and colocation provide a practical middle ground for regulated and latency-sensitive workloads in the US, UK, Germany and across the EU.
A structured scoring model and 90-day assessment help de-risk decisions and align CIO, CTO, CFO and risk stakeholders.
Negotiating cloud contracts with a credible exit strategy improves commercial leverage, even if you ultimately stay mostly cloud-first.
If you suspect 10–20% of your workloads are carrying an outsized share of cloud costs or compliance risk, now is the time to test that hypothesis with real data. The Mak It Solutions team can help you run a focused 90-day assessment, build workload-level TCO models and design a low-risk pilot for cloud repatriation or hybrid architectures.
Ready to see whether cloud repatriation actually pays for your organization? Reach out via the Mak It Solutions services page to book a consultation and get a scoped roadmap your board and regulators can trust.
FAQs
Q : Does cloud repatriation mean leaving AWS or Azure completely, or can it be partial?
A : Cloud repatriation is almost always partial. Most US, UK and EU enterprises move only specific workloads or data sets such as high-cost analytics clusters, latency-sensitive services or regulated databases back to on-prem or colocation while keeping many apps on AWS, Azure, Google Cloud or Oracle Cloud. Surveys suggest only a small minority of organizations aim to move all workloads off public cloud; the typical pattern is a long-term hybrid architecture.
Q : How long does a typical cloud repatriation project take for a mid-sized enterprise?
A : For a mid-sized enterprise in the UK or EU, a focused cloud repatriation project for a handful of workloads usually runs 6–18 months. The first 2–3 months are spent on discovery and TCO modeling, followed by architecture design, pilots and phased migration. Large, highly integrated platforms (for example core banking systems or EHR stacks) take longer, especially where data migration, regulatory approvals and dual-run periods are needed.
Q : Can smaller UK or EU businesses benefit from reverse cloud migration, or is it only for large enterprises?
A : Smaller UK and EU businesses can benefit from reverse cloud migration if they have a few heavy, predictable workloads that dominate cloud spend. For example, a mid-market manufacturer in Germany or a regional retailer in the UK might repatriate a single data warehouse or ERP system to a managed colocation platform while keeping everything else cloud-native. The key is to avoid lifting-and-shifting lightly used workloads and focus on the 10–20% of services that drive most of the cost.
Q : What tools and platforms help monitor performance and cost during and after cloud repatriation?
A : During and after repatriation, you’ll typically combine: cloud billing and FinOps tools (for example AWS Cost Explorer, Azure Cost Management or third-party platforms), infrastructure monitoring (Prometheus, Grafana, Datadog), and APM tools that span on-prem and cloud. Kubernetes platforms, VMware stacks and modern observability suites make it easier to compare performance, error rates and latency across environments. The goal is a single pane of glass for cost, health and compliance signals across cloud-first and on-prem estates.
Q : How do cloud exit clauses and data portability terms in hyperscaler contracts affect a cloud exit strategy?
A : Cloud exit clauses and data portability commitments in your AWS, Azure, Google Cloud or Oracle Cloud contracts can significantly shape your cloud exit strategy. Favourable terms might include guaranteed data export formats, time-bound access after contract end, limited or waived egress fees for migrations, and clear obligations around deleting or anonymizing residual data. Weak or ambiguous clauses can increase both cost and risk when repatriating workloads, so it’s critical to review them with legal, procurement and technology teams well before major renewals or migration waves.