

WebGPU for On-Device AI Inference
On-device AI is moving from novelty to necessity. Users expect private, low-latency experiences that keep data local while still feeling instantaneous. Enter WebGPU the new, low-level GPU API for the web bringing general-purpose GPU compute to modern browsers. With WebGPU, you can run transformer models, segment images, and transcribe audio directly in the browser with performance that was previously reserved for native apps. Chrome shipped WebGPU starting in v113 on desktop and expanded to Android in v121; Firefox added support on Windows in v141; Safari began shipping WebGPU in the Safari 26 beta across Apple platforms in 2025.
In this guide, you’ll learn why to use WebGPU for on-device AI inference, how it works, current browser support, which frameworks to reach for (ONNX Runtime Web, Transformers.js, WebLLM), and the practical steps to ship performant apps. We’ll also cover model optimization (quantization, graph simplification), memory limits, and real-world case studies—including ONNX Runtime Web’s reported 20× speedups vs. multithreaded CPU and 550× vs. single-threaded on some tasks.
Why WebGPU for On-Device AI Inference?
Performance: WebGPU exposes modern GPU features (compute shaders, explicit memory control) and often outperforms WebAssembly for tensor workloads, delivering order-of-magnitude speedups on compatible devices.
Privacy & Compliance: Keeping inference on-device reduces data transfer and exposure, easing GDPR/CCPA concerns and enabling offline usage.
Reach: A single WebGPU code path can target Windows (D3D12), macOS/iOS (Metal), and Linux/Android (Vulkan) via the browser abstraction.
Dev Velocity: Use JS/TS plus familiar bundlers. That means rapid prototyping, easy updates, and no native installs.
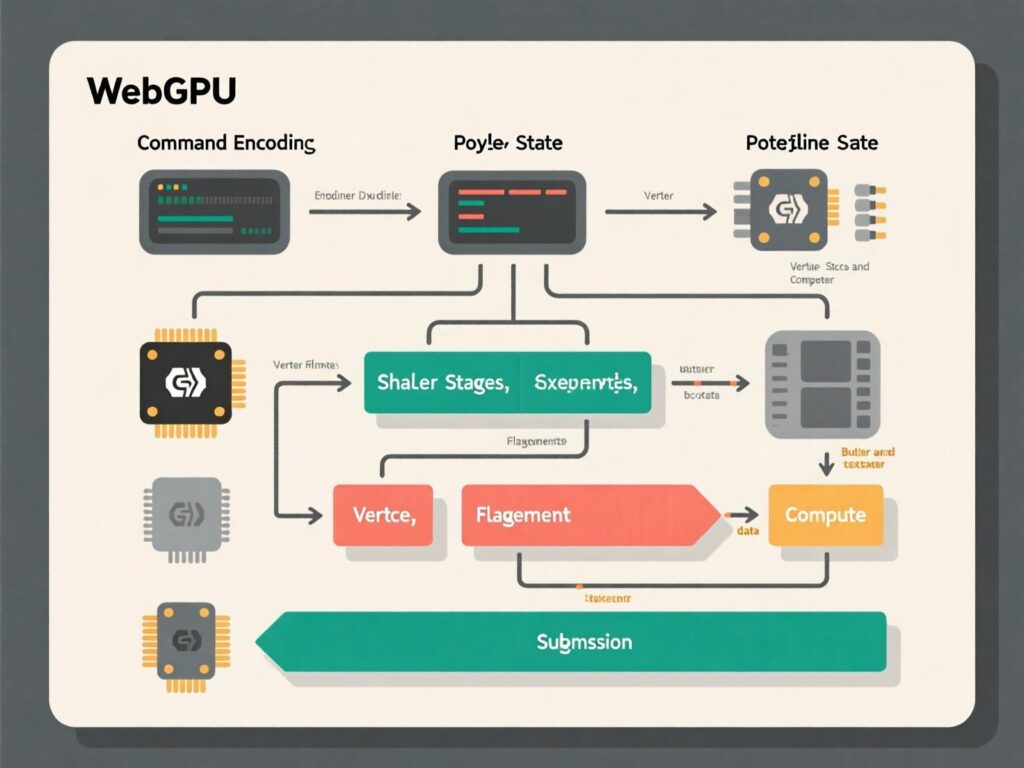
How WebGPU Works (for ML)
At its core, WebGPU provides programmatic access to the system GPU using the WGSL shading language and command buffers. For ML inference:
Upload tensors (as GPU buffers or textures).
Dispatch compute shaders implementing kernels (matmul, attention, conv).
Read back results or keep them on GPU for the next op.
Frameworks like ONNX Runtime Web and Transformers.js generate and orchestrate these workloads for you, exposing simple JavaScript APIs while mapping ops to WebGPU under the hood.
The State of WebGPU Support (2025)
Chrome/Edge (Desktop): WebGPU available since v113.
Chrome on Android: Enabled by default in v121 (Android 12+, Qualcomm/ARM GPUs).
Firefox: Shipped on Windows in Firefox 141 (July 22, 2025), with Mac/Linux coming next.
Safari: Shipping in Safari 26 beta across macOS, iOS, iPadOS, visionOS; previously in Technology Preview
MDN Overview: WebGPU is the successor to WebGL with general-purpose compute.
Takeaway: You can reach most modern Chrome and many Safari/Firefox users today, with progressive enhancement and fallbacks (WASM/WebNN) for the rest.
Frameworks That Support WebGPU Today
ONNX Runtime Web (WebGPU EP)
What it is: A production-grade runtime for ONNX models with a WebGPU Execution Provider (EP).
Why it matters: One codebase that can target webgpu and gracefully fallback to wasm.
Performance: Microsoft reports ~20× over multi-threaded CPU and ~550× over single-threaded CPU on certain browser workloads.
Docs/How-to: Import the WebGPU build or set
executionProviders: ['webgpu','wasm'].
Transformers.js (Hugging Face)
What it is: JS inference for transformers (text, audio, vision) that can target WebGPU (often via ONNX Runtime Web).
Why it matters: Simple pipelines, quantization options (
fp16,q8,q4) suited to WebGPU and WASM backends.
WebLLM (MLC)
What it is: High-performance in-browser LLM inference with WebGPU acceleration; supports Llama 3, Phi-3, Gemma, Mistral, and more.
Why it matters: Privacy-preserving chat and RAG UIs that run locally in the browser, no server required.
Model Optimization for WebGPU Inference
Quantization: Prefer 4-bit or 8-bit for LLMs; 16-bit floats for some vision tasks if memory allows. Transformers.js exposes dtype: "fp16" | "q8" | "q4"; ONNX Runtime offers per-op and dynamic quantization.
Graph Simplification & Fusions: Export clean ONNX, run shape inference, fold constants, and fuse conv+bn.
IO & Memory: Stream model shards; lazy-load tokenizer assets; keep intermediates on GPU when possible to avoid readbacks.
Shard & Cache: Use HTTP range requests, Cache-Control, and Service Workers to cache model parts.
Device Checks: Detect navigator.gpu capability limits (max buffer, storage textures) and pick model sizes accordingly.
WebGPU vs. WebAssembly (and WebNN)
WebGPU: Best when GPU is available and drivers are stable. Great for large matmuls (transformers), attention, and image kernels.
WASM (SIMD + threads): Reliable baseline, broadest compatibility; slower for heavy tensor ops but good fallback.
WebNN: Emerging high-level API that can map to GPU/NPUs. Many teams combine WebGPU + WebNN via ONNX Runtime Web to cover more devices.
Security, Privacy, and Governance
Apple, Google, and Mozilla emphasize safety: GPU access is capability-based and heavily validated to avoid new attack surfaces, with performance overheads minimized in recent builds. Keep PII on-device, constrain prompts/inputs, and apply content filters locally when feasible.
Case Studies: WebGPU in the Wild
Background removal in the browser (vision): ONNX Runtime Web + WebGPU showed ~20× over multithreaded CPU and ~550× over single-threaded on certain pipelines, enabling real-time UX.
Running 7B-parameter LLMs in the browser (LLMs): Google AI Edge (MediaPipe) detailed techniques (streaming, memory mapping) to fit 7B+ models in browsers—key for WebGPU deployments. Google Research
WebLLM (LLM chat): Production-ready chat experiences using WebGPU entirely in-browser; supports streaming and JSON-mode.
How to Ship a WebGPU App
Goal: Run an ONNX model with WebGPU fallback to WASM.
Install packages
Feature detection
Create session with provider order
Prepare inputs & run
Tune env flags (optional)
Bundle & cache
Use code-splitting for model shards, enable long-lived caching, and prefetch on idle.
References: ONNX Runtime Web + WebGPU EP docs, execution provider options, and examples.
Performance Playbook for WebGPU
Quantize aggressively (q4/q8) for LLMs; fp16 for many CNN/ViT models if GPU memory allows.
Reduce transfers: Keep tensors on GPU between ops; avoid frequent
mapAsyncreadbacks.Batch smartly: Micro-batches can maximize occupancy without blowing memory.
Use streaming: Load tokenizer and embedding matrices first to get time-to-first-token down.
Graceful degradation: Detect WebGPU → fallback to WASM → remote inference as last resort.
Testing Matrix Before Launch
Browsers: Chrome 121+ (Android), 113+ (desktop), Safari 26 beta, Firefox 141 (Windows).
Devices: Mid-range Androids (Adreno/Mali), Apple Silicon Macs/iPhones (Metal), Windows laptops (integrated + dGPU).
Edge cases: Memory pressure on 4-GB devices, throttled thermals, background tabs.

Final Thoughts
WebGPU changes what’s possible in the browser. For many workloads—LLMs up to several billion params, real-time vision, speech—WebGPU delivers fast, private, and portable on-device inference with production-ready tooling. With Chrome stable, Firefox joining in 2025, and Safari 26 rolling out, coverage is finally broad enough to ship. Start with ONNX Runtime Web + WebGPU (fallback to WASM), use quantized models, and test across a small device matrix. The result: native-feeling AI apps, zero install, global reach.
CTA: Ready to prototype? Grab our starter and ship your first WebGPU inference demo this week.
FAQs
1) How does WebGPU differ from WebGL for AI?
A . WebGL targets graphics; compute is indirect via fragment shaders. WebGPU exposes compute shaders, explicit buffers, and modern GPU features, making tensor ops (matmul/attention) efficient for ML.
Schema expander: Highlight compute shaders and general-purpose GPU support.
2) How do I enable WebGPU in Chrome/Android?
A . Chrome supports WebGPU on desktop since v113 and Android (12+) since v121 by default on Qualcomm/ARM GPUs. Keep Chrome updated.
Schema expander: Mention chrome://gpu to verify.
3) How can I fall back if WebGPU isn’t available?
A . Use ONNX Runtime Web with executionProviders: ['webgpu','wasm']. WASM (SIMD+threads) is a reliable baseline.
Schema expander: Show feature detection for navigator.gpu.
4) How big of a model can I run with WebGPU?
A . Depends on GPU memory and browser limits. With sharding and quantization, 7B-class LLMs are viable on some devices; smaller models provide broader coverage.
Schema expander: Reference streaming and memory mapping techniques.
5) How do I pick quantization levels?
A . Start with q4/q8 for LLMs; test fp16 for vision. Tools in Transformers.js and ONNX Runtime help.
Schema expander: Mention accuracy-latency trade-offs.
6) How secure is WebGPU for user data?
A . Vendors added strict validation and sandboxing; Safari 26 beta notes performance validation with minimized overhead. Keep data on device and minimize logging.
Schema expander: Add PII retention guidance.
7) How do I benchmark fairly?
A . Warm up the graph, pin the tab (avoid background throttling), measure median of N runs, and include cold-start + cache-warm numbers.
Schema expander: Recommend Web Tracing Framework markers.
8) How can WebGPU help with battery life?
A . GPU offloads can finish work sooner and idle; measure real device power with platform tools and avoid unnecessary readbacks.
Schema expander: Remind to cap FPS and batch size.
9) How do I ship models legally?
A . Check each model’s license (weights and tokenizer). Host only permitted artifacts; offer opt-in downloads for large weights.
Schema expander: Include license compliance checklist.