
RAG vs Fine Tuning for LLMs: Cost, Risk, Scale
RAG vs Fine Tuning for LLMs: Cost, Risk, Scale

RAG vs Fine Tuning for LLMs: Cost, Risk, Scale
For most enterprises, RAG vs fine tuning is not a binary choice. Use retrieval-augmented generation (RAG) when you need fresh, governed access to documents across regions, and fine-tuning when you want a model to perform a narrow, stable task with consistent tone and behaviour. The safest path is usually RAG-first, then add targeted fine-tuning once usage data shows clear, high-volume workflows where lower latency and tighter control justify the extra investment.
Introduction
Across the United States, United Kingdom, Germany and the wider European Union, enterprise teams are caught between “just add RAG to a foundation model” and “let’s fine-tune everything.” CTOs, Heads of Data/AI, enterprise architects and compliance leaders all feel the pressure to pick the right path for RAG vs fine tuning before budgets and regulators catch up.
This guide gives you a practical decision framework rather than another theory piece: how RAG and fine-tuning actually work in enterprise environments, how to choose based on cost, risk and GEO constraints, and how hybrid architectures and migration paths look in real LLM systems. By the end, you should know whether you’re a RAG-first, fine-tuning-first or hybrid team and what to do next.
RAG vs Fine-Tuning.
RAG (retrieval-augmented generation) keeps your data in external stores and retrieves it at query time, while fine-tuning permanently adapts model weights on curated examples. In enterprises, RAG is usually better for fast-changing knowledge and document-heavy workflows; fine-tuning is better for narrow tasks, stable knowledge and brand tone/style control.
What is Retrieval-Augmented Generation (RAG) in Enterprise Context?
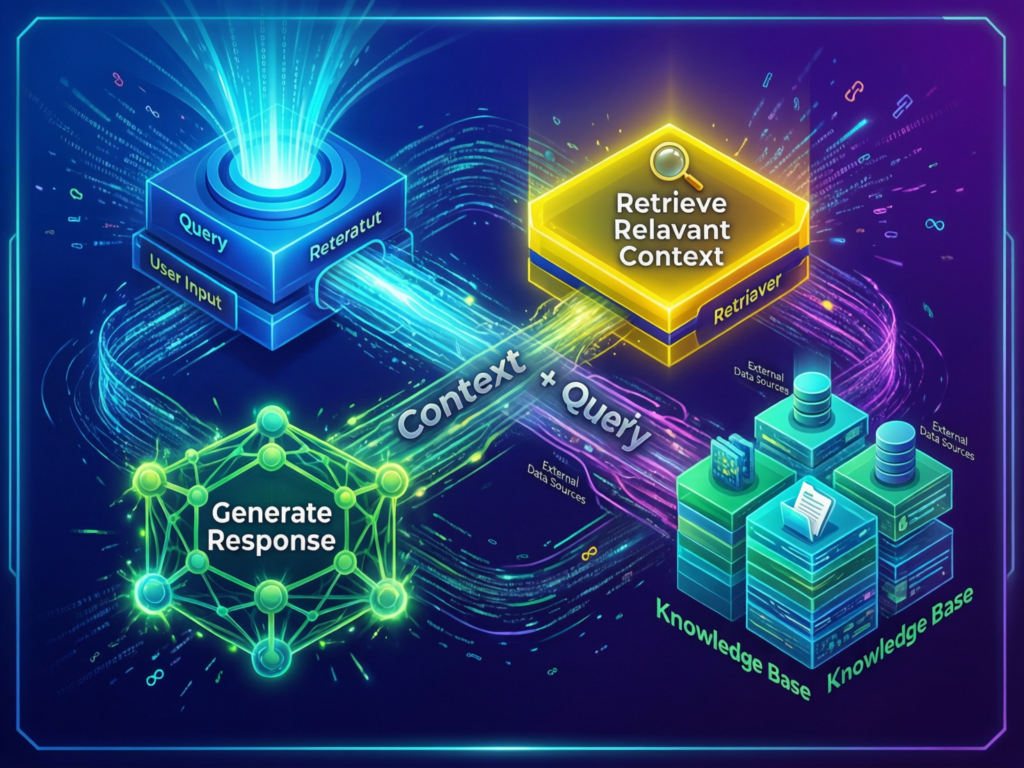
In enterprise terms, RAG means your LLM doesn’t “remember” everything in its weights; instead, it looks up relevant documents, embeddings or APIs on the fly and then generates an answer grounded in those results. A typical retrieval augmented generation architecture has connectors into SharePoint, Confluence, CRM, ticketing systems and data warehouses; an ingestion pipeline for chunking and embedding; a vector database and retriever; and then an LLM that consumes retrieved passages as context.
For business stakeholders, the easiest mental model is “Google-like enterprise search plus a smart summariser.” Instead of manually searching policies, contracts and Jira tickets, a RAG assistant can answer: “What changed in our New York and London leave policies in 2024?” and cite the underlying HR docs. This is why retrieval augmented generation vs fine tuning is especially attractive where knowledge changes weekly and must be filtered by region, role and permission.
What is Fine-Tuning for LLMs?
Fine-tuning for LLMs means taking a pre-trained base or instruction model and updating its weights on curated examples so it behaves like your domain expert. Unlike prompt engineering (where you keep the model fixed and craft prompts) or instruction tuning (where vendors train general-purpose assistants), enterprise fine-tuning targets specific behaviours: classification, routing, domain jargon and voice.
Teams fine-tune models to label tickets, triage incidents, route emails, follow brand tone, or follow strict policies with minimal prompting. In architectural decisions about RAG vs fine tuning for LLMs, you can think of fine-tuning as “baking in” the skill, while RAG “plugs in” the knowledge. Often, the best-performing systems combine both: a fine-tuned router or agent that decides when to call RAG, tools or traditional APIs.
Side-by-Side Table: RAG vs Fine-Tuning for Enterprise LLMs
| Dimension | RAG (Retrieval-Augmented Generation) | Fine-Tuning |
|---|---|---|
| Data freshness | Updates as fast as your indexes refresh; ideal for changing docs and FAQs. | Frozen at last training run; requires re-training to reflect new knowledge. |
| Governance & audit | Document-level citations, per-query logs, easier right-to-be-forgotten handling. | Harder to “unlearn” individual records; requires strict training-data governance. |
| Infra complexity | Needs connectors, pipelines, vector DB, retriever and LLM. | Needs training pipeline, experiment tracking and model registry; simpler inference path. |
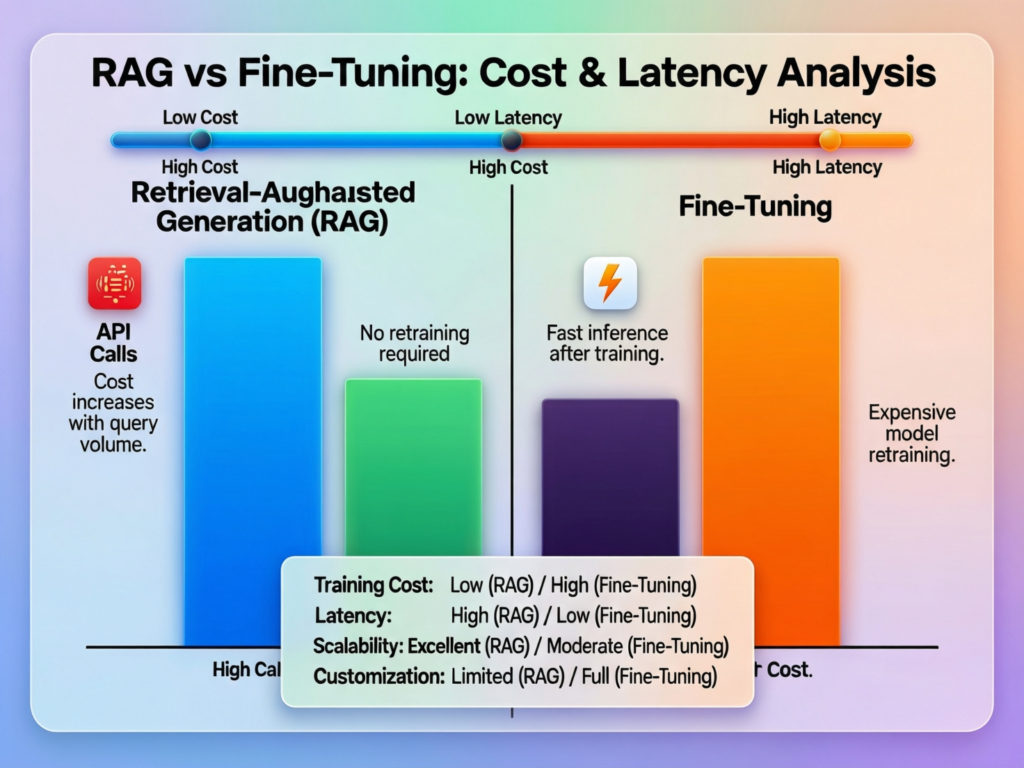
| Latency | Extra hops for retrieval and cross-region traffic; usually higher p95 latency. | Single model call; can be significantly faster at scale. |
| Cost profile | Lower upfront; higher per-request tokens (longer prompts) and retrieval infra costs. | Higher upfront data/experimentation cost; lower per-call token usage for narrow tasks. |
| Explainability | Easier to show “which documents we used” via citations. | Harder to attribute decisions; requires evals and model documentation. |
| Offline capability | Depends on connectivity to indexes and data sources. | Fine-tuned models can run on edge or air-gapped infra more easily. |
Remember: this is not a binary decision. Many modern stacks use RAG for knowledge access and a small portfolio of fine-tuned models for routing, style and specialist tasks.
Enterprise Decision Framework When to Use RAG vs Fine-Tuning
Use RAG when your source data changes frequently, lives in many systems and must remain in-region (US/UK/EU) with document-level audit trails. Use fine-tuning when the task is narrow, repetitive and stable like classification, routing or enforcing brand tone especially once you’ve learned from RAG usage data.
Decision Criteria.
A practical RAG vs fine tuning decision framework starts with four axes.
Data volatility & freshness
Fast-changing policies, product catalogs or support content → RAG-first.
Slow-changing tax rules or underwriting guidelines → fine-tuning becomes attractive once patterns stabilise.
Domain complexity & specialisation
Everyday language with long documents (contracts, manuals) → RAG.
Highly specialised jargon, templates and labels → fine-tune a classifier or assistant.
Governance & compliance requirements
Strong GDPR/DSGVO, UK-GDPR, HIPAA, PCI DSS or SOC 2 obligations push you toward RAG, where you can keep sensitive data in-region, exclude subsets from indexes and honour deletion requests.
Fine-tuning can still be viable for pre-approved, de-identified datasets with clear lineage and retention policies.
Geography & data residency
US-only hosting with sector rules (e.g. healthcare, banking).
UK-only (NHS and Open Banking), or EU-only with Schrems II constraints on cross-border transfers.
Germany-only deployments, where data centres in Frankfurt or Munich are non-negotiable.
For a UK SME in financial services, a “RAG vs fine tuning decision framework for UK SMEs” might score RAG high on governance and cost, and fine-tuning high on UX for a narrow mortgage-advice assistant leading to a hybrid choice.
RAG vs Fine-Tuning Use Cases in US, UK, Germany & EU
US examples
US healthcare: RAG vs fine tuning for US healthcare HIPAA-compliant LLM
RAG-first: surface HIPAA-compliant policies, clinical guidelines and patient education content while keeping PHI in-region and excluding ultra-sensitive notes from the index.
Fine-tuning: add a small fine-tuned model to classify intents (billing vs clinical vs admin) and enforce health-system tone.
US banks and Open Banking data
Hybrid: RAG over product terms, disclosures and API docs; fine-tuned models for transaction categorisation and fraud pattern classification.
UK examples
UK financial services & Open Banking
RAG over FCA, Open Banking and internal policy docs; fine-tune a model to generate compliant responses and reason over structured risk data.
NHS-style patient support.
RAG is preferred for triaging questions against clinical pathways and public information while keeping data under NHS-style governance.
Fine-tuning may support very narrow triage flows, but only on rigorously curated datasets.
Germany/EU examples
RAG vs fine tuning DSGVO-konform für Unternehmen
German enterprises often want RAG-only for internal copilots so that all documents stay in Frankfurt or Berlin data centres and can be removed by data-protection teams.
For Industrie 4.0 use cases (e.g. classifying machine incidents), fine-tuned models running near the edge can deliver low-latency predictions and avoid constant retrieval. (Mak it Solutions)
Across US, UK, Germany and EU, RAG tends to win for knowledge assistants and multi-system copilots; fine-tuning wins for narrow, structured tasks; hybrid wins where both exist in the same journey.
When to Move from RAG-Only to a Fine-Tuned Model in Production
The key signal for when to move from RAG to a fine tuned model in production is traffic concentration: if 60–80% of your queries fall into a handful of intents, you are probably over-paying in tokens and latency to handle them with pure RAG. Logs will show repetitive conversations where prompts grow more complex just to keep the model inside policy.
Other migration signals.
Very high traffic on a narrow set of workflows (e.g. password resets, basic claims queries).
Prompt bloat: RAG prompts with dozens of instructions and guardrails.
Latency pressure: user journeys where even 500–800ms extra hurts conversion.
A simple migration path.
Start with RAG, using a general model plus retrieval.
Collect logs and human feedback; cluster intents and identify your top workflows.
Curate high-quality examples for those workflows and fine-tune a smaller model.
Route matching traffic to the fine-tuned model and keep RAG as a fallback and knowledge layer.
Architecture Choices for LLMs RAG, Fine-Tuning and Hybrid
For LLM architectures, RAG adds a retrieval layer and vector store around mostly off-the-shelf models, while fine-tuning modifies the model itself. Most modern enterprise stacks start with RAG-first architectures, then add targeted fine-tuning for routing, tone and specialised tasks, creating a hybrid approach that evolves with usage.
Reference RAG Architecture for Enterprise LLMs
A reference RAG architecture looks like this.
Data sources HR portals, policy wikis, CRM, ticketing tools, file shares.
Ingestion connectors pull content, normalise formats and apply access controls.
Chunking & embedding split content into passages and generate vector embeddings.
Vector DB & metadata store store embeddings with IDs, permissions and GEO tags.
Retriever & re-ranker select the top-k chunks for a given query, optionally re-ranked.
LLM generate an answer conditioned on retrieved context.
In a London- and Berlin-based deployment, you might keep vector DB clusters in UK and EU cloud regions, keeping logs and indices in-region to align with GDPR/DSGVO and UK-GDPR. US teams in San Francisco or New York can still run similar stacks, but are freer to use cross-region services.
Reference Fine-Tuning and Customisation Patterns
Modern LLM customisation strategies go beyond full fine-tuning of a giant base model:
Parameter-efficient methods like LoRA/PEFT and adapters.
Prompt-tuning for lightweight behaviour changes.
Small, specialised models for classification and routing that sit alongside a bigger general model.
These plug into MLOps/LLMOps pipelines: data versioning, experiment tracking, CI/CD for models and controlled rollouts. For some workloads such as scoring payments risk or eligibility you may pair fine-tuned models with traditional microservices and databases rather than RAG, because the task is more about structured decisioning than document retrieval.
Hybrid RAG + Fine-Tuning Architecture Patterns
A hybrid RAG and fine tuning approach typically looks like.
RAG for knowledge, fine-tuned router for intent
A fine-tuned classifier decides whether a query should hit RAG, a deterministic API or a specialised model.
Fine-tuned domain model + light RAG on top for citations
A model trained on support transcripts handles tone and flow, while a small RAG layer fetches relevant policies for grounding.
Over time, many teams follow an evolution path: POC chatbot → RAG MVP over a few systems → hybrid architecture with orchestration, observability and clear lanes for RAG vs fine-tuning. This kind of thinking aligns well with Mak It Solutions’ work on enterprise AI agents and multi-system automation for US, UK and EU teams. (Mak it Solutions)
Cost, Latency & Operations RAG vs Fine-Tuning
RAG usually has lower upfront cost but higher per-request complexity, as you pay for retrieval and larger prompts. Fine-tuning requires more upfront investment in data and experiments but can reduce token usage and latency at scale. Over the long term, high-volume, narrow workloads often favour fine-tuning; diverse, knowledge-heavy workloads favour RAG or hybrid.
Cost Breakdown Infra, Token Usage and TCO
When you compare RAG vs fine tuning cost, think in three buckets:
Infrastructure
RAG: vector DBs, ingestion jobs, retrievers, observability for retrieval quality.
Fine-tuning: training runs (GPU time), model registries, evaluation pipelines.
Token usage
RAG: longer prompts with retrieved docs; more context = more tokens.
Fine-tuned models: can often handle a task with shorter prompts, lowering per-call cost, especially for high-volume APIs.
Ongoing maintenance
RAG: re-index docs as they change; maintain connectors.
Fine-tuning: schedule re-training when schemas, policies or user behaviour change.
For a RAG vs fine tuning cost comparison for high volume LLM API, imagine 10 million monthly calls. At that scale, a fine-tuned model handling 70% of traffic with short prompts can materially cut spend and latency, while RAG handles the remaining 30% of long-tail knowledge queries.
Latency, UX and Scalability at Enterprise Scale
RAG adds steps: vector search, re-ranking and sometimes cross-region hops. That means higher p95 latency, especially if an EU-based front-end calls a US-hosted model or index. For interactive chat in Berlin or London, cross-Atlantic round trips can be noticeable.
Fine-tuned models, by contrast, can run as a single call on GPUs or CPUs close to the user, which makes RAG vs fine tuning latency comparisons especially important for real-time UX. When combined with smart batching and autoscaling, fine-tuned APIs can hit tight SLAs, while RAG can be reserved for actions where an extra 300–800ms is acceptable. (Medium)
On scalability, RAG introduces more moving parts indexes, retrievers, sync jobs but also de-risks vendor changes, because you can swap out the underlying LLM without rebuilding everything. Fine-tuning improves throughput and predictability but ties you more closely to a given model family.
LLMOps for RAG and Fine-Tuning in Production
Successful LLMOps for RAG and fine tuning treat both as first-class citizens.
Monitoring
RAG: retrieval hit rate, citation quality, hallucination rate, permission leaks.
Fine-tuning: label drift, performance regression by segment, fairness and bias.
Release processes
RAG: rolling out new indexes or re-ranked models behind feature flags.
Fine-tuning: blue/green deploys of new model versions with offline and online evals.
Vendors like Monte Carlo Data and Matillion highlight how important robust data pipelines and observability are for trustworthy AI; similar principles apply when you’re shipping enterprise LLM systems, not just dashboards.
Governance, Risk & Compliance Across US, UK and EU
RAG often makes it easier to respect GDPR/DSGVO, UK-GDPR and sector rules because sensitive data can stay in-region, be excluded from indexes and be deleted or redacted later. Fine-tuning can be safer for highly constrained, pre-approved datasets but requires strong processes around training data selection, logging and model audits under frameworks like the EU AI Act.
Nothing in this article is legal, compliance or financial advice; always work with your own counsel and internal risk teams before making decisions.
Data Privacy, Data Residency and Cross-Border Transfers
For RAG vs fine tuning data privacy and data residency, the key question is: “Where does the data go, and can we delete it later?”
RAG strengths
Vector stores and logs can be hosted in-region (e.g., Frankfurt or London).
You can filter out particular records from indexes, important for right-to-be-forgotten and data minimisation.
Schrems II risks can be mitigated by keeping personal data in EU/UK regions and only sending derived signals elsewhere.
Fine-tuning considerations
Training datasets may cross borders, especially if your model provider trains in US regions.
Once data is encoded into weights, “unlearning” specific individuals is difficult and often requires full or partial retraining.
This doesn’t mean fine-tuning is impossible in regulated environments; it just means you should treat each fine-tuned model like a data asset with its own lineage, DPIA and retention plan.
Regulated Industries.
In regulated industries, RAG vs fine tuning patterns vary.
US healthcare (HIPAA)
RAG over de-identified notes, clinical guidelines and policies, with PHI kept in-region.
Fine-tuned models for specific coding or triage tasks, trained on carefully governed datasets. (Founders Forum Group)
UK public sector and healthcare
For bodies similar to NHS, RAG is natural for patient-facing FAQs and staff knowledge assistants where content is semi-public but workflows are sensitive.
Fine-tuning might power internal triage or prioritisation models, but only after thorough assurance.
Germany/EU financial services
BaFin-regulated banks and insurers can use RAG for policy search and regulatory copilots with logs stored in-country.
Fine-tuned models can handle risk scoring and anomaly detection when backed by strong governance and model validation.
Security Controls, Auditability and the EU AI Act
For RAG vs fine tuning security controls, RAG has a built-in advantage in traceability: you can log which documents were retrieved for each answer and show citations, which maps well to the EU AI Act’s emphasis on transparency and logging for high-risk systems. (Artificial Intelligence Act)
Fine-tuning, on the other hand, demands.
Documented training datasets with clear provenance and consent.
Model cards and evaluation reports explaining limitations.
Ongoing monitoring for drift and incidents.
Cloud-agnostic architectures using neutral components like open-source vector DBs and standard formats help UK/EU teams meet tender requirements that discourage deep lock-in to a single AI vendor.
Hybrid Strategies, Migration Paths and Vendor Lock-In
Most enterprises should treat RAG and fine-tuning as complementary. Start with RAG for broad coverage and governance, then fine-tune targeted models where traffic, quality and latency justify the investment, all within a cloud-agnostic, GEO-aware architecture.
3-Phase Roadmap: RAG-First → Targeted Fine-Tuning → Full Hybrid
A practical roadmap.
Phase 1 — RAG-only, fast POCs
Launch a RAG assistant over your top repositories in New York, London and Berlin.
Prove value on internal knowledge search and customer support use cases first.
Phase 2 — Targeted fine-tuning
Use logs to identify high-volume, narrow workflows.
Fine-tune models for routing, summarisation or template generation where you can measure ROI.
Phase 3 — Full hybrid
Introduce an orchestrator/router that chooses between RAG, fine-tuned models and deterministic APIs.
Align this with enterprise AI agent strategies and governance processes you already use. (Mak it Solutions)
Cloud-Agnostic and GEO-Aware Design for US, UK, Germany & EU
For US, UK, Germany and EU organisations, cloud-agnostic and GEO-aware design means:
Separating storage and compute by region (e.g., US East for American workloads, London and Frankfurt for European ones).
Using open vector DBs and neutral formats so you can move between AWS, Azure and Google Cloud over time. (Mak it Solutions)
Reusing multi-cloud patterns you might already be exploring for edge vs cloud AI workloads or sovereign cloud strategies.
Evaluating Vendors and Platforms Through the RAG vs Fine-Tuning Lens
When you evaluate vendors cloud providers, LLM platforms or SaaS copilots ask.
Which models are supported, and how well do they handle RAG vs fine-tuning?
Is there first-class support for retrieval augmented generation architecture (connectors, vector DBs, eval tools)?
What does the fine-tuning pipeline look like (data governance, approvals, rollback)?
How mature is observability and documentation for enterprise LLM governance?
Look at how players like IBM, Red Hat and Elastic talk about open, hybrid AI, and how newer search-centric vendors such as Glean position RAG as part of the stack.
Mak It Solutions can then help you compare these options against your existing cloud estate and AI roadmap, drawing on work in conversational AI, AI content moderation and multi-cloud architectures for global teams. (Mak it Solutions)
Enterprise Checklist & Next Steps
Quick Checklist: Are You a RAG, Fine-Tuning or Hybrid Team?
Answer “yes” or “no” to each:
Do your key documents change weekly or monthly (policies, FAQs, specs)
Do you operate across multiple regions (US, UK, EU) with strict data residency?
Are most user questions about “what does policy X say?” rather than “should we approve Y?”
Do you see a handful of high-volume, repetitive intents in logs?
Do you already run MLOps (CI/CD for models, feature stores, evals)
Are p95 latency and throughput critical (e.g., transaction scoring, real-time CX)
Do you need document-level citations for governance reviews?
Are you under frameworks like EU AI Act, HIPAA or BaFin supervision?
Roughly: mostly “yes” to 1–3 & 7 → RAG-first; mostly “yes” to 4–6 → fine-tuning-first; a mix across all → hybrid.
What to Prepare Before an Architecture Workshop
Before a RAG vs fine-tuning workshop, prepare.
A high-level system map of your apps, data warehouses and document stores by region.
A data inventory noting where personal, financial and health data lives.
A list of regulatory obligations (GDPR/DSGVO, UK-GDPR, HIPAA, PCI DSS, SOC 2, EU AI Act).
Historical volumes: API calls, tickets, chats, forms.
Cost constraints and performance targets.
A cross-functional attendee list: engineering, data, security, compliance, legal and operations.
This upfront work lets architecture sessions move beyond theory into concrete “Phase 1 in 90 days” roadmaps.

Key Takeaways
RAG vs fine tuning is rarely an either/or decision; RAG wins for fast-changing, document-heavy knowledge, while fine-tuning shines for narrow, high-volume tasks with stable rules.
Start RAG-first to cover more ground quickly and stay inside GDPR/DSGVO, UK-GDPR and sector regulations, then fine-tune where traffic, latency and UX justify it.
Hybrid architectures RAG plus fine-tuned routers and task models are emerging as the default pattern for enterprise LLM stacks.
Cost, latency and TCO depend on workload mix: at scale, fine-tuning can reduce token usage for hot paths while RAG handles the long tail.
Cloud-agnostic designs and strong LLMOps practices help you avoid vendor lock-in and stay aligned with evolving regulations like the EU AI Act.
Global adoption of AI is still accelerating, with enterprise generative AI markets projected to grow at well over 30% CAGR toward 2030, so decisions you make about RAG vs fine tuning today will shape cost, risk and capability for years.
If you’d like a concrete RAG vs fine-tuning roadmap for your organisation, we can help you map workloads, regulations and GEO constraints into a clear 3-phase plan. Share your current architecture and target regions, and our Editorial Analytics Team and solution architects will propose a RAG-first, hybrid or fine-tuning-centric approach that fits your budget and risk profile.( Click Here’s )
You can then choose to move forward with an architecture workshop, a scoped pilot (e.g. customer support copilot, internal policy assistant) or a broader enterprise AI platform engagement whatever best matches where you are today.(Mak it Solutions)
FAQs
Q : Is RAG always cheaper than fine-tuning for enterprise LLM workloads?
A : Not always. RAG has lower upfront cost because you don’t retrain the model, but each request can be more expensive due to vector search and longer prompts. Fine-tuning requires investment in data curation, training runs and evaluation, yet for high-volume, narrow use cases it can reduce per-call token usage and infrastructure cost. The cheapest option depends on your traffic mix, latency targets and whether your workloads are knowledge-heavy or task-heavy.
Q : Can I start with a general-purpose model and add RAG later without re-architecting everything?
A : Yes, if you plan ahead. Start with an architecture that separates your application, orchestration, model layer and data layer. Use an API abstraction so you can plug a retriever and vector store into the flow later. Many teams begin with a general-purpose model plus prompt engineering, then add RAG as a new path in the orchestration layer, without rewriting front-ends or business logic. It’s much harder if retrieval logic is hard-coded into every service.
Q : How do small engineering teams manage RAG vs fine-tuning if they don’t have a full MLOps function?
A : Smaller teams should usually go RAG-first with managed components from their cloud or LLM platform, and only fine-tune where it really moves the needle. Use managed vector DBs, hosted models and built-in eval tools instead of running everything yourself. For fine-tuning, start with parameter-efficient approaches like LoRA and rely on vendor pipelines for experiments and deployment. Over time, you can grow MLOps capabilities as usage and complexity justify it.
Q : What are the most common mistakes enterprises make when choosing between RAG and fine-tuning?
A : Common mistakes include fine-tuning too early without good data, trying to solve messy search problems with a single model, and ignoring governance. Some teams over-index on “AI magic” and forget that retrieval quality or label quality matters as much as model size. Others treat RAG and fine-tuning as substitutes rather than complementary tools. A better approach is to map use cases, label which are knowledge-heavy vs decision-heavy, and then choose RAG, fine-tuning or hybrid accordingly.
Q : Does running my own vector database make GDPR and data residency easier to manage than fine-tuning?
A : Running your own vector database in EU or UK regions can make GDPR and data residency easier to control, because you decide exactly where embeddings and logs live and who can access them. You can exclude certain records, re-index when data changes and honour deletion requests. Fine-tuned models, by contrast, often run on shared infrastructure and encode data in weights, which are harder to edit. Both approaches can be compliant, but self-hosted or region-hosted RAG gives you more granular levers.
[…] guide explains what prompt injection attacks in LLMs are, how LLM tool abuse turns text into real-world actions, and how to design, test and govern […]