
Cloud Repatriation Strategy: A CIO Guide for US & Europe
Cloud Repatriation Strategy: A CIO Guide for US & Europe

Cloud Repatriation Strategy: A CIO Guide for US & Europe
Cloud repatriation is the process of moving applications, data and services from public clouds like AWS, Azure or Google Cloud back to on-premises data centers, private clouds or colocation. CIOs typically consider cloud repatriation when specific workloads become too expensive, hard to govern or difficult to keep compliant in hyperscaler environments, and a hybrid model offers better cost, control and resilience.
Put simply, cloud repatriation is selective “reverse migration” inside a broader hybrid cloud strategy, not an all-or-nothing exit from the cloud.
Introduction
For a decade, “cloud-first” sounded like a safe default. Public cloud gave US, UK and EU enterprises agility, global reach and a way to escape aging data centers. But by 2025, many CIOs are seeing a different picture: rising cloud bills, tricky egress fees, new regulations, AI data-gravity and boards asking, “Are we really in the right place for these workloads?”
Cloud repatriation is the response to that question. It means moving selected apps and data off public clouds and back into on-premises, private cloud or colocation environments when the economics, compliance or performance no longer make sense in hyperscaler regions. Surveys suggest that around 70–80% of organizations have already repatriated at least some workloads, even if only a small fraction are exiting the cloud entirely.
In this guide, we’ll look at what cloud repatriation actually is, how it differs from traditional cloud migration and pure FinOps, when the math works, how US/UK/German/EU regulations shape your options, and how CIOs can build a pragmatic roadmap from first workload assessments to a sustainable hybrid cloud repatriation strategy.
What Is Cloud Repatriation and How Does It Differ from a Traditional Cloud Migration?
Cloud repatriation moves workloads off public cloud back to on-prem/private environments, usually for cost, compliance or performance reasons. Traditional cloud migration moves workloads into the cloud for agility and scalability.
Cloud repatriation explained in plain language
Cloud repatriation is the process of relocating applications, data and services from hyperscalers like Amazon Web Services, Microsoft Azure or Google Cloud Platform back into your own data centers, private clouds or colocation facilities. You can think of it as “reverse cloud migration” or “de-clouding” but usually done selectively, not as a full retreat.
Most enterprises don’t “turn everything off.” Instead, they analyze workloads one by one and move those where they can run more cheaply, more predictably or more compliantly on infrastructure they own or tightly control. A practical working definition is.
Cloud repatriation is the process of relocating workloads from hyperscalers to your own or partner facilities to improve cost control, compliance, performance or governance.
Cloud repatriation vs traditional cloud migration vs optimization
A traditional cloud migration moves workloads to the cloud—trading capex for opex, gaining elasticity and offloading undifferentiated heavy lifting. Cloud repatriation moves specific workloads from the cloud back to private or colocated environments, often after the organization has learned where cloud actually adds value and where it doesn’t.
It helps to separate three levers:
Cloud optimization / FinOps rightsizing instances, using reserved/spot capacity, cleaning up idle resources and modernizing architectures while staying on the same provider.
Re-architect in the cloud moving from lift-and-shift VMs to managed PaaS, serverless or containers.
Selective repatriation moving chosen workloads back to data center, private cloud or colocation when unit economics, compliance or latency clearly favor that move.
Repatriation should sit alongside FinOps and architecture modernization as one tool in a broader optimization toolkit, not a religious stance “for” or “against” cloud.
How cloud repatriation fits with hybrid and multi-cloud strategies
For most US and European enterprises, repatriation doesn’t end in a 100% on-premises world. It ends in hybrid: some workloads in your own facilities, others still in AWS, Azure or GCP regions such as London, Frankfurt or Amsterdam.
You might also layer multi-cloud on top: keeping global customer-facing services on a hyperscaler, while moving data-heavy analytics to colocation or using EU-focused providers like IONOS Cloud, CloudKleyer or UpCloud for sovereignty-sensitive data. In other words, repatriation is a specific kind of workload placement decision inside a hybrid/multi-cloud strategy not the opposite of it.
Cloud Repatriation Economics & FinOps: When Does the Math Work?
Why can cloud repatriation reduce long-term costs for some workloads but increase costs for others?
Cloud repatriation can reduce long-term costs when you have large, predictable workloads or storage-heavy data that can be run more efficiently on owned or colocated infrastructure. For bursty, experimental or highly managed workloads, moving off public cloud often increases total cost of ownership once you factor in hardware, facilities and staffing. ([learning.dell.com][5])
Key cost drivers to model include:
Egress and data movement analytics and AI workloads that constantly pull large datasets out of cloud storage pay heavily in egress fees.
Storage and network long-lived object storage, logs and backups can become expensive at hyperscaler list prices.
Managed service markup premium PaaS/SaaS (databases, observability, AI services like Splunk or Cloudian-backed storage) add convenience but also margin.
Usage pattern 24/7 steady-state workloads behave very differently from short, spiky dev/test or campaign traffic.
Repatriation typically pays off when.
You have large, predictable baselines (e.g., core banking in Frankfurt, ERP in London, manufacturing systems in Detroit).
You run storage-heavy data lakes and archives with high read/write rates.
Analytics or AI workloads incur significant egress to downstream systems.
It can increase costs when
Workloads are highly elastic or seasonal (Black Friday e-commerce, Super Bowl campaigns, UK tax season).
Teams rely heavily on managed PaaS/SaaS that would need to be rebuilt and operated in-house.
You underestimate the cost of skills, tooling and 24/7 operations.
Micro-answer
Cloud repatriation pays off when unit economics are predictable and infrastructure can be run more cheaply in owned or colocated facilities than in public cloud; for spiky or heavily managed workloads, staying on public cloud is usually cheaper.
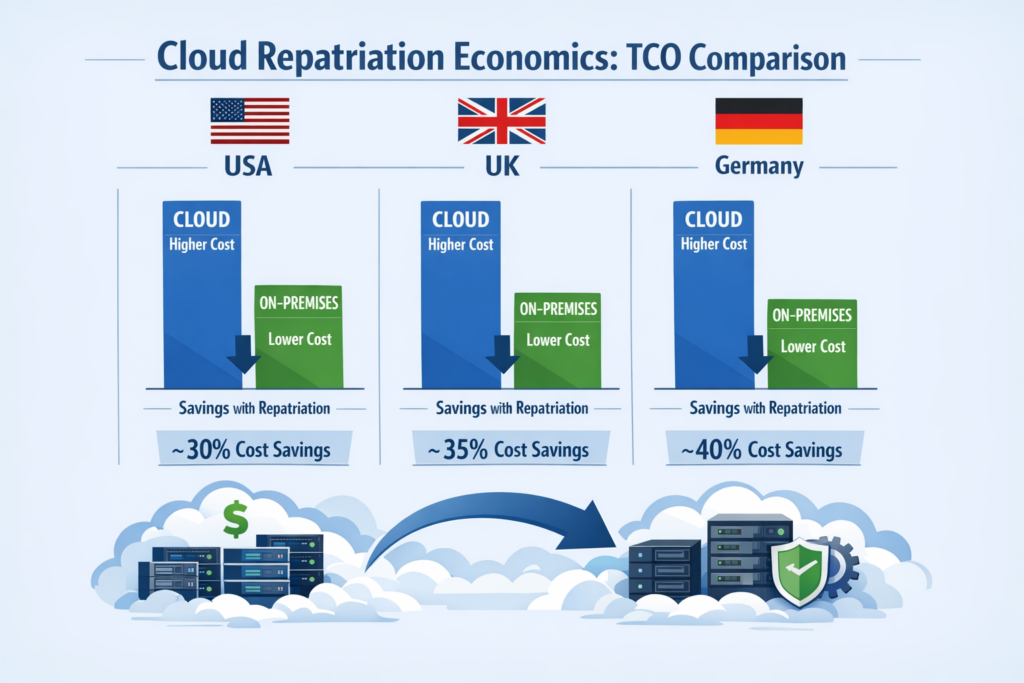
Cloud vs on-prem TCO comparison in the US, UK and Germany
Total cost of ownership (TCO) must include more than hardware. For US, UK and German enterprises, you should model: infrastructure (servers, storage, network), colocation fees, power and cooling, connectivity, software licenses, security tools and staffing.
A few practical patterns
United States (e.g., New York or Austin)
Power can be relatively affordable and there’s dense colocation competition, but salaries for SRE and platform teams are high. US SaaS firms often repatriate analytics or storage to cut hyperscaler egress and then use optimized web platforms (for example, those built by partners like Mak It Solutions) to serve front-end traffic.
United Kingdom (London/Manchester)
Colocation and power costs are higher, but so are GDPR and UK-GDPR pressures. Some UK banks and NHS-linked healthcare providers keep regulated datasets in UK-only facilities while leaving customer-facing portals and mobile backends in UK cloud regions.
Germany / EU (Frankfurt, Berlin, Amsterdam)
Data residency, BaFin guidance and digital sovereignty agendas mean many institutions prefer EU-owned or EU-operated environments. Here, the cost of not complying with GDPR or DORA can dwarf small differences in hosting price.
In practice, you’re trading known fixed costs (capex + colocation + team) against variable cloud bills. A 2023 IDC report found that around 80% of companies expected to repatriate some workloads within two years, primarily due to rising cloud costs and data sovereignty concerns.
FinOps vs cloud repatriation: optimize, re-architect or move home?
A disciplined CIO treats repatriation as a later lever, not the first move. The usual sequence looks like this:
FinOps first rightsizing, reserved/spot instances, cleaning up idle resources, enforcing budgets and using observability (e.g., BI platforms like Mak It Solutions’ [business intelligence services][11]) to get clarity on unit costs.
Re-architect selectively move appropriate workloads onto managed PaaS, serverless or container platforms to improve elasticity and efficiency.
Repatriate only where justified once FinOps gains are largely captured, model a 3–5-year view comparing “optimize in place” vs “hybrid vs repatriate” for each workload, including double-run periods and migration risk.
Why can cloud repatriation reduce long-term costs for some workloads but not others?
Because cost outcomes depend on workload shape: steady, storage-heavy workloads often run cheaper in owned or colocated environments, while bursty, spiky or heavily managed-service-dependent workloads usually remain cheaper on public cloud.
For many CIOs in New York, London or Berlin, the right answer is not “cloud or on-prem,” but “which workloads belong where over the next 3–5 years?”
Why Are Some Enterprises Leaving the Public Cloud After “Cloud-First”?
Enterprises are not “anti-cloud”; they’re reacting to rising costs, stricter regulation, data-gravity and resilience concerns by moving specific workloads to environments where they have more control over cost, risk and performance.
Cost, predictability and vendor lock-in pressures
Cloud bills have quietly become one of the largest line items in tech P&L. Surveys show more than 40% of IT leaders experienced unexpected cloud cost spikes in the past year, with many reporting unbudgeted expenses between $5,000 and $25,000.
For CFOs in New York or London, the pain points are familiar:
Escalating COGS/COR as cloud spend grows faster than revenue.
Unpredictable egress and overage fees, especially for data platforms.
Perceived lock-in around proprietary databases, AI services and monitoring stacks like Splunk.
Cloud repatriation gives CIOs leverage: when you can genuinely move a workload to colocation or on-prem, negotiations with hyperscalers shift from “take it or leave it” to “we have options.”
Performance, latency and data-gravity for AI and analytics workloads
Data-gravity describes the tendency of large datasets to attract compute and services to them. For AI and analytics workloads, moving compute closer to data whether in a Frankfurt colocation, a US manufacturing plant or a UK telco edge site can cut both latency and cost.
Typical candidates include:
Low-latency trading platforms in London or New York
Telco edge networks processing traffic near towers across Germany or the wider EU.
AI/ML training on massive proprietary datasets where constant shuttling to and from cloud object storage becomes untenable.
In many cases, a hybrid AI architecture wins: models and training data live in high-bandwidth private environments, while customer-facing APIs still run in public cloud regions. Articles like Mak It Solutions’ [Enterprise AI Agents for US, UK & EU show how these AI layers can sit on top of hybrid infrastructure.
Real-world case studies and what they reveal
The Dropbox example is famous: by moving major storage workloads off AWS and onto its own infrastructure, Dropbox reportedly achieved cumulative savings of around $75 million over two years, primarily through lower storage and networking costs.
More recently, companies like 37signals (Basecamp and HEY) have publicly described multi-million-dollar annual savings after buying their own hardware and exiting large chunks of AWS usage.
The lesson from these stories and from smaller SaaS, fintech and healthcare providers in the US, UK and EU is consistent:
They repatriated select workloads, not entire estates.
They landed in hybrid models with strong automation (Kubernetes, object storage, Infrastructure as Code).
They treated repatriation as both a technical and cultural change, upskilling teams for data-center-like operations again.
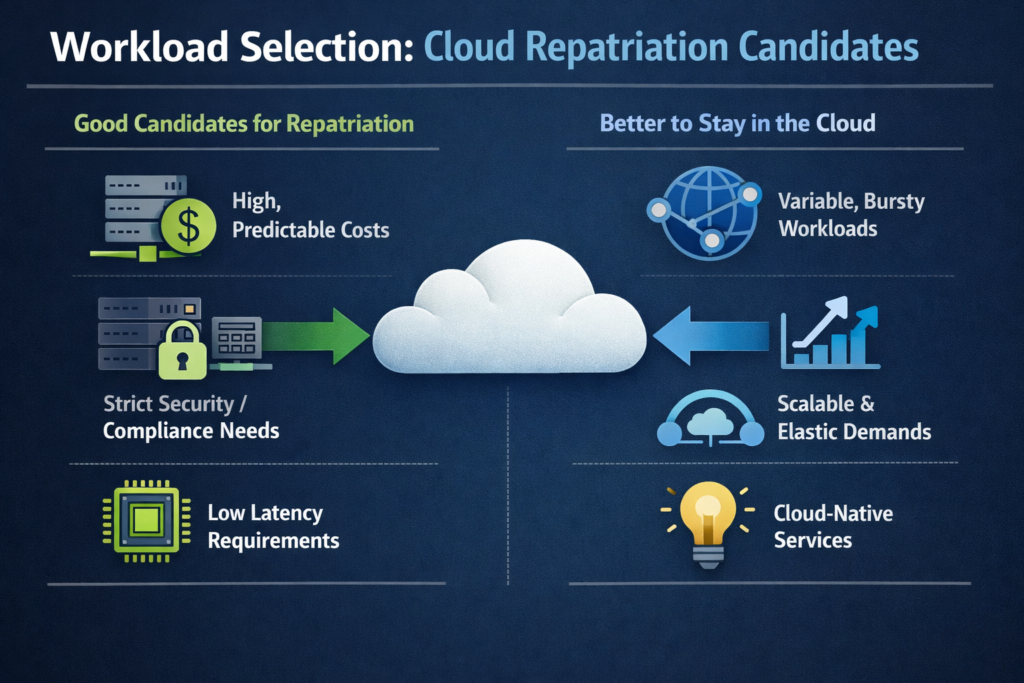
What Types of Workloads Are Best Suited to Move Back On-Prem?
The best repatriation candidates are steady, storage-heavy, compliance-sensitive or latency-critical workloads where you can predict demand and operate infrastructure more efficiently than your hyperscaler.
High, predictable baseline usage and storage-heavy workloads
If you can confidently say, “This runs 24/7 and we know roughly how it will grow,” repatriation is worth a look. Classic examples include:
Large file repositories, media archives and backup systems.
Log platforms and observability data stores.
Analytics data lakes with predictable query patterns.
Here, object storage platforms on-prem or in colocation combined with modern web services (for example, built on top of Mak It Solutions’and business intelligence offerings) can deliver cloud-like usability at lower TCO over 3–5 years.
Regulated, sensitive and sovereignty-bound data sets
Workloads subject to GDPR/DSGVO, UK-GDPR, HIPAA, PCI DSS or SOC 2 are often prime candidates for either repatriation or sovereign cloud.
Examples:
German banks aligning with BaFin expectations and DORA, keeping core transactional systems in EU-only data centers.
UK public sector and NHS workloads with strict residency rules and public trust constraints.
US healthcare and payments workloads balancing HIPAA and PCI DSS obligations with multi-region availability.
Sometimes you don’t go all the way back on-prem; you might instead move to EU-centric providers like IONOS Cloud or to sovereign regions while keeping less sensitive workloads in public cloud. Mak It Solutions’ work on shows a similar pattern in another region careful mapping of workloads to regulatory zones which transfers directly to EU and UK contexts.
When public cloud is still the better home
Repatriation is not for everything. Public cloud is usually still the right choice for.
Highly elastic apps and seasonal campaigns where you value “scale to zero.”
Early-stage products where rapid iteration matters more than hardware efficiency.
Global content delivery, mobile backends and experimentation (e.g., LLM proof-of-concepts) with uncertain demand.
In other words: don’t repatriate these unless you have a very specific reason, such as regulatory pressure that can’t be met in public cloud or extreme per-unit costs that you can clearly beat in a private environment.
What types of workloads are best suited to move back on-prem instead of staying in the public cloud?
The strongest candidates are steady, storage-heavy, compliance-sensitive or latency-critical workloads where demand is predictable and your team can operate infrastructure more efficiently than the hyperscaler.
How Do Compliance and Data Sovereignty Rules Influence Cloud Repatriation?
In US, UK and EU markets, privacy, data-sovereignty and operational resilience rules can effectively force certain workloads closer to home, making cloud repatriation or sovereign-cloud moves a compliance and risk-management issue, not just a cost play.
Mapping privacy and sector regulations to hosting choices
CIOs need a clear map from regulation to infrastructure options:
GDPR / DSGVO (EU) drives strict rules for personal data processing, cross-border transfers and data subject rights; Schrems-related uncertainty around US data access has made some EU regulators wary of non-EU cloud dependencies.
UK-GDPR closely aligned but enforced by the ICO, with specific guidance for sectors like health and financial services.
HIPAA (US) pushes strong controls for protected health information; recent enforcement trends focus heavily on security risk analysis and vendor management.
PCI DSS / SOC 2 influence how cardholder data and critical SaaS platforms are architected and audited across US, UK and EU operations.
For some scenarios, you can stay on hyperscalers using regional data residency features. In others especially where regulators are concerned about foreign laws such as the US CLOUD Act boards push towards sovereign cloud or actual on-prem repatriation.
Sector examples: banking, healthcare and public sector
Banking (e.g., BaFin-regulated institutions in Germany) increasingly expected to manage concentration risk on a small number of hyperscalers, maintain exit strategies and prove that critical services can run in alternative environments.
Healthcare (NHS in the UK, hospital groups in the US and Germany) must reconcile GDPR/UK-GDPR or HIPAA with AI and analytics workloads, sometimes preferring local data centers or sovereign cloud for high-sensitivity workloads.
Public sector and critical infrastructure often under political pressure to keep data within national or EU borders.
These sectors rarely exit the cloud entirely—they design hybrid landing zones with clear boundaries: citizen or patient data here, low-risk workloads there.
Digital sovereignty, DORA and resilience expectations
In the EU, the Digital Operational Resilience Act (DORA) sharpens expectations for financial institutions’ ICT risk management, including third-party concentration and exit planning. That translates into.
Contractual caps on dependence on any single cloud provider.
Mandated exit strategies with proven, tested fallback options.
A push to maintain some on-prem or secondary facilities capacity.
Cloud repatriation projects often emerge directly from DORA or similar reviews when boards realize, “We don’t actually know how we’d exit hyperscaler X if we had to.”
Micro-answer.
In heavily regulated sectors, compliance and sovereignty rules often make repatriation or sovereign cloud not just a cost optimization, but a regulatory safeguard and resilience requirement.

How Can a CIO Decide Whether to Optimize Cloud Spend or Start a Cloud Repatriation Project?
CIOs should treat repatriation as one option in a structured decision framework: exhaust FinOps opportunities first, then repatriate only those workloads where business, risk and cost modelling clearly support the move.
A cloud exit strategy checklist from assessment to run-state
A practical checklist looks like this.
Inventory workloads capture cost profile, criticality, data sensitivity, performance SLAs, architecture dependencies and vendor lock-in for each major system.
Classify by hosting fit score each workload along three paths: “optimize in place,” “re-architect on cloud,” or “repatriate/hybrid.”
Quantify 3–5-year scenarios model baseline cloud optimization vs partial repatriation vs hybrid, including hardware refresh cycles, colocation contracts and staffing.
Define exit artefacts cloud exit playbooks, RTO/RPO assumptions, failover runbooks and test plans.
Pilot and iterate start with 1–3 workloads where the business case is strongest, then refine your framework.
This checklist can double as the backbone of a board-ready cloud exit strategy and aligns well with the kind of structured, analytical work Mak It Solutions delivers in its.
Building a business case and board-ready story by region
Boards in the US, UK and EU will ask slightly different questions, but your core narrative is the same.
Cost cloud vs on-prem vs hybrid TCO scenarios, clearly documented.
Risk & compliance how repatriation supports GDPR/UK-GDPR, HIPAA, PCI DSS, DORA and local regulator expectations.
Resilience how reducing hyperscaler concentration risk improves operational resilience.
You can strengthen your case with industry data, for example: IDC and others reporting that around 80% of organizations have repatriated at least some workloads, with many citing cost and sovereignty as primary drivers.This is not financial advice; always do your own research and validate benchmarks against your own estate.
Selecting partners, platforms and tools for reverse cloud migration
Few enterprises repatriate alone. Typical partners include.
Colocation providers in hubs like London, Frankfurt and Amsterdam.
Systems integrators and managed service providers with modern on-prem stacks (Kubernetes, on-prem object storage, observability).
Regional providers like CloudKleyer or UpCloud that complement hyperscalers with EU-centric infrastructure.
On the tooling side.
Data migration tools for databases, object storage and file systems.
Validation and cutover orchestration platforms.
A strong BI/analytics layer again, services like Mak It Solutions’ business intelligence services and web development capabilities to give leadership real-time visibility into performance and cost across hybrid estates.
How can a CIO decide whether to optimize cloud spend or start a cloud repatriation project?
CIOs should run a structured workload-by-workload assessment, apply FinOps and architecture optimizations first, then pursue repatriation only for workloads where 3–5-year cost, risk and resilience modelling clearly favors moving off public cloud.
Practical Roadmap: From Pilot Workloads to a Sustainable Hybrid Model
Preparing your landing zone: DCs, colocation and on-prem object storage
Before moving a single VM, you need a modern landing zone.
Confirm data center or colocation readiness (power, cooling, cross-connects to AWS/Azure/GCP regions in London, Frankfurt or Amsterdam)
Design standardized platforms Kubernetes clusters, on-prem object storage (e.g., Cloudian-style S3-compatible platforms), service meshes and CI/CD pipelines that give cloud-like agility.
Mak It Solutions often combines these layers with custom dashboards and control planes so CIOs and FinOps teams can see cloud vs on-prem costs and KPIs in one place, similar to how they would view multi-cloud analytics in existing BI platforms.
Minimizing downtime, double-run costs and migration risk
Repatriation projects fail when they run in “double pay” mode for too long or when cutovers break SLAs. To avoid that:
Use phased migrations and pilot workloads to learn before moving mission-critical systems.
Apply patterns like blue-green or canary cutovers, with transaction replay and shadow traffic where possible.
Plan explicit rollback paths back to the cloud if early issues appear.
A well-run project aims to keep the parallel-run window short and focused, not months of duplicated spend.
Measuring success: FinOps, resilience and user experience KPIs
Finally, define how you’ll know you’ve succeeded. Typical KPIs include:
Unit cost per transaction, per GB stored, or per analytics query tracked across cloud and on-prem.
Resilience metrics incident and outage rates, RTO/RPO adherence, failover test success.
User experience latency and availability for key user journeys in New York, London, Berlin and beyond.
Governance matters as much as technology: set up a cross-functional steering group (CIO, CISO, CDO, Finance) that periodically revisits placement decisions optimize vs repatriate vs re-cloud as prices, regulations and business priorities change.

Key Takeaways
Cloud repatriation is selective, workload-by-workload “reverse migration”, not an anti-cloud crusade.
It tends to pay off for steady, storage-heavy or compliance-sensitive workloads, while elastic or experimental workloads usually belong on public cloud.
US, UK, German and EU regulations (GDPR/DSGVO, UK-GDPR, HIPAA, PCI DSS, DORA) can push certain workloads toward sovereign cloud or on-prem environments.
CIOs should follow a structured decision framework, exhausting FinOps and cloud modernization before repatriating.
A sustainable target state is almost always hybrid, with strong automation, observability and governance connecting cloud and on-prem worlds.
If your cloud bill keeps creeping up, or regulators are asking uncomfortable questions about sovereignty and exit plans, it’s time to look beyond “cloud-first” and toward a more balanced cloud repatriation strategy.
Mak It Solutions helps US, UK, German and wider EU enterprises design practical workload placement strategies, from multi-cloud cost optimization to secure hybrid architectures that respect GDPR, HIPAA and local regulator expectations.
Share a short description of your estate and we’ll help you identify 2–3 pilot workloads where repatriation, optimization or sometimes doing nothing is actually justified.
FAQs
Q : Is cloud repatriation a step backwards or part of a modern hybrid cloud strategy?
A : Cloud repatriation is not a retreat to the past; it’s a way to correct over-rotation to public cloud and land in a balanced hybrid model. By moving only the right workloads home and keeping others on hyperscalers, enterprises gain better cost control, resilience and compliance while still benefiting from cloud-native services where they add the most value.
Q : How long does a typical cloud repatriation project take for a mid-size enterprise?
A : For a mid-size US or European enterprise, a focused repatriation program for 3–10 workloads usually runs 9–18 months end-to-end. The timeline depends heavily on complexity, regulatory requirements and how modern your on-prem stack is; organizations that already run Kubernetes, on-prem object storage and CI/CD pipelines typically move faster than those rebuilding data center capabilities from scratch.
Q : What hidden costs do companies underestimate when moving workloads back on-premises?
A : Commonly underestimated costs include network connectivity (private links to cloud and branch sites), observability and security tooling, 24/7 operations teams and the effort to re-platform managed cloud services. Many also under-budget the double-run period where workloads run in both cloud and on-prem; careful planning and phased cutovers are essential to keep that window short and controlled.
Q : Can cloud repatriation help reduce vendor lock-in without fully leaving hyperscalers?
A : Yes. Even if you keep most workloads on public cloud, selectively repatriating key data stores or platforms can restore negotiating power and reduce technical lock-in. Some enterprises keep their “system of record” databases or data lakes in colocation or private cloud while using hyperscalers primarily for elastic front-ends, global distribution and managed services that are easier to swap or re-implement later.
Q : How should US, UK and EU enterprises choose between sovereign cloud, colocation and full on-prem repatriation?
A : The choice hinges on regulatory strictness, internal skills and desired control. Highly regulated banks or public-sector agencies in Germany or the UK may prefer sovereign cloud or national providers to align with GDPR/DORA and reduce exposure to foreign laws, while tech-savvy SaaS firms in the US may favor colocation or self-managed data centers to optimize long-term TCO. Many land on a mix: sovereign or national cloud for the most sensitive workloads, colocation for large data platforms, and hyperscalers for global, customer-facing applications.
[…] multi cloud strategy is worth the effort when you need regulator-driven diversification, stronger resilience, […]