
FinOps for AI: A Practical Playbook for GPU Cost Control
FinOps for AI: A Practical Playbook for GPU Cost Control

FinOps for AI: A Practical Playbook for GPU Cost Control
FinOps for AI applies cloud financial operations to GPU-heavy AI workloads so engineering, finance and product can see and control the cost of training and inference in real time. Instead of just buying “cheaper GPUs”, it focuses on sustainable unit economics like cost per token or per 1,000 model queries so teams in the US, UK and EU can scale AI safely, quickly and profitably.
Introduction
AI has gone from side project to board-level priority in just a couple of years and your GPU invoice probably tells the story better than any slide deck. Worldwide AI spending is forecast to approach roughly $1.5 trillion in 2025, fuelled heavily by infrastructure and GPU demand.
For many US SaaS companies, London fintechs and German enterprises, GPU compute is now the single largest piece of AI infrastructure cost, often 40–60% of technical cloud budgets.Because AI workloads are experimental, spiky and often under-instrumented, CFOs and CIOs are getting surprised by invoices they can’t easily explain.
At the same time, regulations like GDPR, UK-GDPR, the EU AI Act and sector rules for healthcare (HIPAA, NHS guidance) or banking (BaFin, PCI DSS) make “just move it to the cheapest region” a non-starter for many teams.
This is where FinOps for AI comes in. It brings structured AI infrastructure cost management to GPU-heavy workloads, so you can keep shipping models across regions like Dublin, London, Frankfurt or Oregon without torching margins or violating local rules.
How Can FinOps for AI Cut Runaway GPU Cloud Costs?
FinOps for AI cuts runaway GPU cloud costs by making trade-offs between performance, speed and spend visible and negotiable across engineering, finance and product. Instead of arguing about “expensive GPUs” in the abstract, teams get concrete metrics like cost per experiment, cost per token and cost per 1,000 queries, and adjust architecture, models and pricing accordingly.
Done well, this discipline doesn’t slow AI teams down; it shortens feedback loops, exposes waste early and enables smarter bets on where GPUs deliver the most value.
FinOps for AI vs Generic Cloud Cost Management
Classic cloud cost programs were built around VMs, storage and steady-state workloads; they assume you can tag everything, right-size a few instances and lock in savings plans. AI breaks that.
With FinOps for AI, you still care about tagging and waste but you add concepts like token-based billing from providers, the split between training and inference, and full model lifecycle costs. For example:
A US SaaS team might track the combo of GPU hours + API tokens for a generative AI feature.
A UK team building NHS-aligned diagnostics might focus on cost per validated study plus data residency overhead.
This is FinOps for MLOps and generative AI pipelines, not just generic cloud clean-up.
Why GPU Workloads Break Traditional Cloud Cost Optimization Models
GPU-heavy workloads are bursty, experimental and often poorly scheduled. Teams spin up massive training jobs on AWS, Microsoft Azure or Google Cloud, leave experiments running over weekends, or reserve high-end GPUs “just in case” then underutilize them.
On top of that, the most desirable GPU SKUs are scarce and pricey, especially in US East, London or Frankfurt regions, so people grab whatever is available, not what is economical. The result: poor forecasting, idle but reserved GPUs, over-provisioned clusters for low-traffic inference and nasty overages when a feature launch drives unplanned traffic.
FinOps for AI in US SaaS, UK Fintech and EU Enterprises
US SaaS in San Francisco or Austin
Shipping AI features weekly, using managed LLM APIs and in-house models. Without FinOps for AI, they can’t see cost per customer or per feature, and pricing lags behind reality.
London fintech
Running GPU clusters for fraud detection under UK-GDPR and FCA expectations. They must balance region choice, encryption and strict logging with sustainable unit economics per transaction.
German or EU enterprise in Berlin or Paris
Under BaFin or other EU supervisors, plus GDPR and the EU AI Act. They need cost transparency across EU regions (Frankfurt, Dublin, Netherlands, Nordics) and may explore providers like Genesis Cloud to keep data and GPUs in Europe.
Across all three, FinOps for AI is how they regain control of GPU spend without killing innovation.
What Is FinOps for AI and How Is It Different From Traditional Cloud FinOps?
FinOps for AI is an extension of cloud FinOps focused specifically on AI infrastructure, data and model costs, with GPUs as a primary driver of spend. It introduces AI-specific metrics like cost per training run, cost per token and cost per 1,000 queries and builds cross-functional workflows between data science, MLOps, platform engineering and finance.
Where traditional FinOps says “tag everything and cut waste”, FinOps for AI says “understand how every GPU dollar maps to a model, a feature, a user and a business outcome”.
Core Principles of FinOps for AI Teams
Common principles include.
Shared accountability for AI costs across engineering, product, finance and leadership.
Real-time visibility into GPU utilization monitoring and reporting, not just monthly invoices.
Unit economics firs cost per token, per experiment, per model, per customer segment.
Embedded FinOps champions inside AI and ML teams in New York, London, Berlin or Amsterdam, not just in a central finance function.
The FinOps Foundation reports that a fast-growing share of practitioners now explicitly manage AI and GPU spend, with AI costs touching nearly all FinOps teams.
GPU Economics for AI Workloads
To practice FinOps for AI, teams need a working model of GPU economics.
Pricing models
On-demand, reserved/committed use, spot/preemptible, or fixed-price/bare-metal.
Patterns
Training tends to be long-running and tolerant of interruptions; inference tends to be latency-sensitive and bursty.
Levers
Utilization, throughput (tokens/sec, queries/sec) and intelligent placement across regions and providers.
This isn’t just about one hyperscaler: teams in the EU often compare AWS, Azure and Google Cloud with EU-centric GPU clouds like Genesis Cloud or private/bare-metal platforms like OpenMetal.
FinOps Metrics for GPU Workloads
A practical FinOps for AI scorecard usually includes.
GPU utilization (per node, per cluster, per team)
Cost per training job or per experiment
Cost per token or per 1,000 queries for inference
Cost per model, per feature and per product
As maturity grows, these roll up into customer-level and product-level margins, so leaders can decide whether a new generative AI feature in a US or UK market really pays for its GPU habit.
What Are the Main Cost Drivers of GPU-Heavy AI Workloads in the Cloud?
The main cost drivers for GPU-heavy AI workloads are GPU type and region, training duration, model size, inference traffic patterns, storage and data movement. Many teams focus only on GPU hourly rates but underestimate non-GPU line items like networking, logging, observability and compliance features that become significant at scale.
In other words: your “GPU problem” is probably a broader AI infrastructure cost management problem.
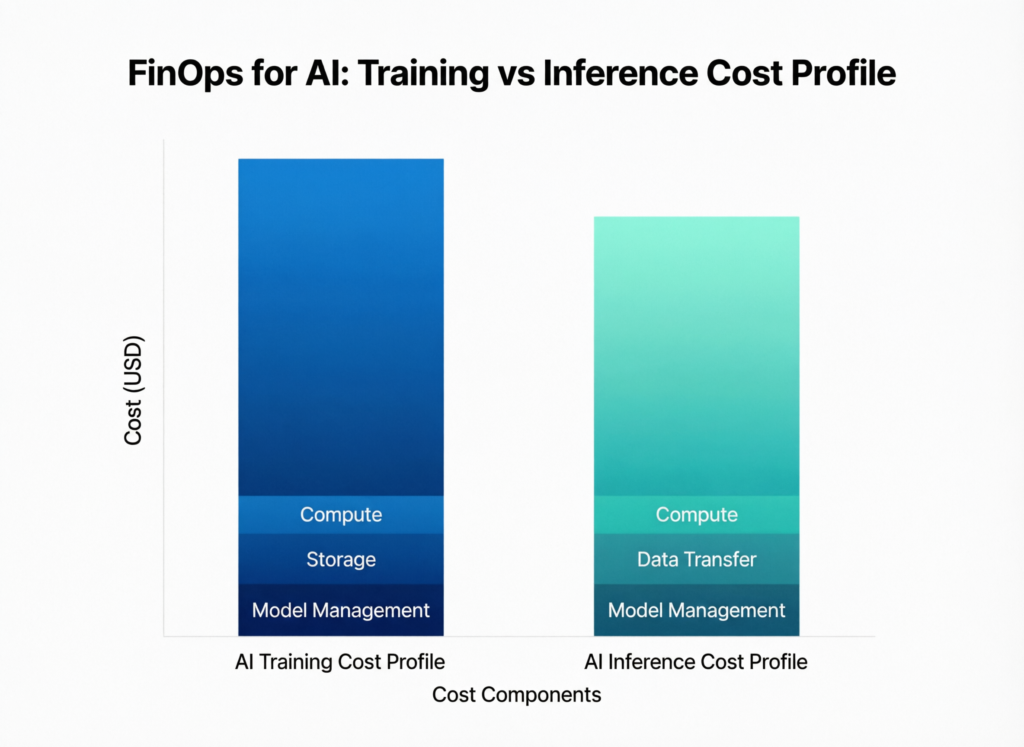
Training vs Inference.
Training and inference behave very differently.
Training
Long-running, often bursty and highly experimental. Cost is driven by GPU hours, checkpoint frequency and experiment hygiene. The key metric: cost per experiment or cost per successful model.
Inference
Tied to request volume, latency SLOs and concurrency. Here, cost per 1,000 queries or per 1,000 tokens is more useful, especially for customer pricing in US and EU SaaS markets.
Mature teams track both and make architecture decisions (e.g., batching, caching, distillation) with those metrics front and center.
Hidden Costs Around AI Infrastructure
Beyond GPUs, you’ll see.
Storage for datasets, features and model checkpoints
Cross-region data egress and traffic replication
Observability, logging and security tooling
Backup, retention and legal hold policies
These “hidden” costs expand under GDPR, UK-GDPR and sector rules like NHS guidance or BaFin supervision, because you may need extra logging, replicas in EU regions (Frankfurt, Dublin, Netherlands, Nordics) and stricter data residency.
Region and Provider Differences for GPU Pricing
GPU pricing can vary dramatically.
Between US regions and EU regions within the same provider
Between hyperscalers and alternative GPU clouds some reports suggest hyperscalers can be roughly twice as expensive as certain alternatives for comparable GPU capacity.
FinOps for AI treats region and provider choice as active levers: perhaps running German workloads on an EU-sovereign GPU cloud like Genesis Cloud, and experimentation on cheaper spot GPUs in US regions.
Practical GPU Cost Optimization Strategies With FinOps for AI
FinOps teams can reduce GPU costs for AI training and inference without slowing innovation by combining engineering tactics (right-sizing, scheduling, model optimization) with financial guardrails (budgets, alerts, chargeback). The emphasis is on continuous optimization rather than one-off “cost-cutting projects”.
Think of it as AI workload right-sizing and autoscaling, plus smarter purchasing and governance.
GPU Cost Optimization Best Practices for AI Training
For training workloads.
Use spot/preemptible GPUs where your pipelines can tolerate restarts.
Schedule big jobs for cheaper hours or regions when permitted by data residency.
Avoid over-provisioned instances; scale cluster size based on batch size and throughput.
Practice experiment hygiene: auto-kill abandoned runs, reuse checkpoints, expire old artifacts and track cost per experiment in your MLOps tools.
Right-Sizing GPU Instances Across AWS, Azure and GCP
Right-sizing AI workloads means matching model needs to instance shape:
Choose appropriate GPU families (e.g., NVIDIA A100/H100 vs RTX) and memory footprints.
Mix CPU and GPU nodes for data prep vs main training.
Use auto-scaling and bin-packing for inference clusters so GPU nodes scale with real demand.
Articles like Mak It Solutions’ AWS vs Azure vs Google Cloud comparison already show how multi-cloud choices affect cost and performance FinOps for AI builds on that knowledge with GPU-centric metrics.
Scheduling, Autoscaling and Avoiding Idle GPUs
Idle GPUs are pure margin leak. Your FinOps for AI playbook should include:
Job schedulers and queues that align GPU time with workload timing
Idle timeouts for dev/test clusters
Nightly clean-ups of abandoned notebooks and demo environments
Autoscaling policies that scale down aggressively when traffic drops
This is where platforms built for gpu utilization monitoring and reporting become invaluable.
Model Optimization to Reduce GPU Cost
Finally, reduce the amount of GPU you need in the first place:
Quantization and pruning to shrink models
Distillation smaller models mimicking larger ones for production
Smarter batching and caching to improve throughput
Lower-latency architectures for inference so you can meet SLOs with fewer GPUs
These model-level tactics directly reduce GPU hours and lower cost per token and per query.
Governance, Chargeback and Compliance for AI Spend
Without governance, AI costs grow faster than FinOps teams can react. Recent benchmarks show that although formal cloud cost programs nearly doubled year-over-year (to over 70% of respondents), mean cloud efficiency actually dropped from ~80% to ~65%, largely due to uncontrolled AI spending.
FinOps for AI adds clear chargeback, forecasting and compliance-aware controls on top of the technical optimizations.
Chargeback and Showback for GPU and Token Costs
You can’t manage what you can’t allocate. Practical steps.
Enforce tagging by team, project, model and environment.
Allocate shared GPU clusters by proxies: tokens, jobs, experiments or API calls.
For a US SaaS, allocate cost per feature or product line; in a London bank, by business unit or risk domain; in a healthcare setting (NHS-aligned or US HIPAA workloads), by clinical application or hospital group.
This makes cost per token tracking and cost per experiment part of everyday engineering language.
AI Cost Forecasting Models in FinOps
Forecasting AI costs means combining.
Historical spending by model, region and environment
Product roadmaps (new features, regions, channels)
Business scenarios (user growth, new EU markets, France vs Netherlands vs Nordics launch)
FinOps teams often maintain GPU capacity and budget forecasts similar to how SREs forecast traffic—only now the constraints are GPU availability, EU AI Act compliance and enterprise deal pipelines.
Compliance-Aware AI FinOps in Regulated Sectors
Healthcare, financial services and public sector workloads face additional constraints:
Healthcare HIPAA in the US, NHS guidance in the UK and local regulators in the EU.
Banking BaFin in Germany, plus EU and local banking supervisors.
Payments PCI DSS and often SOC 2/ISO 27001 for platforms.
FinOps for AI must model the cost of required encryption, logging, retention, sovereign cloud options and cross-border restrictions not just assume “the cheapest region wins”.
How Should Organizations in the EU Adapt AI FinOps Practices for the EU AI Act and Data Act?
The EU AI Act entered into force in August 2024, with obligations for certain AI categories especially GPAI providers and high-risk systems phasing in through 2025 and beyond.
From a FinOps for AI angle, EU organizations should.
Tag and track high-risk systems and compliance-driven features separately.
Capture compliance-driven costs extra logging, explainability tooling, DPIAs, switching-friendly architectures so legal and product leaders see their impact.
Evaluate EU-based GPU providers (e.g., Genesis Cloud) and sovereign/private clouds (OpenMetal, on-prem) where the EU Data Act or customer contracts demand portability and cloud switching.
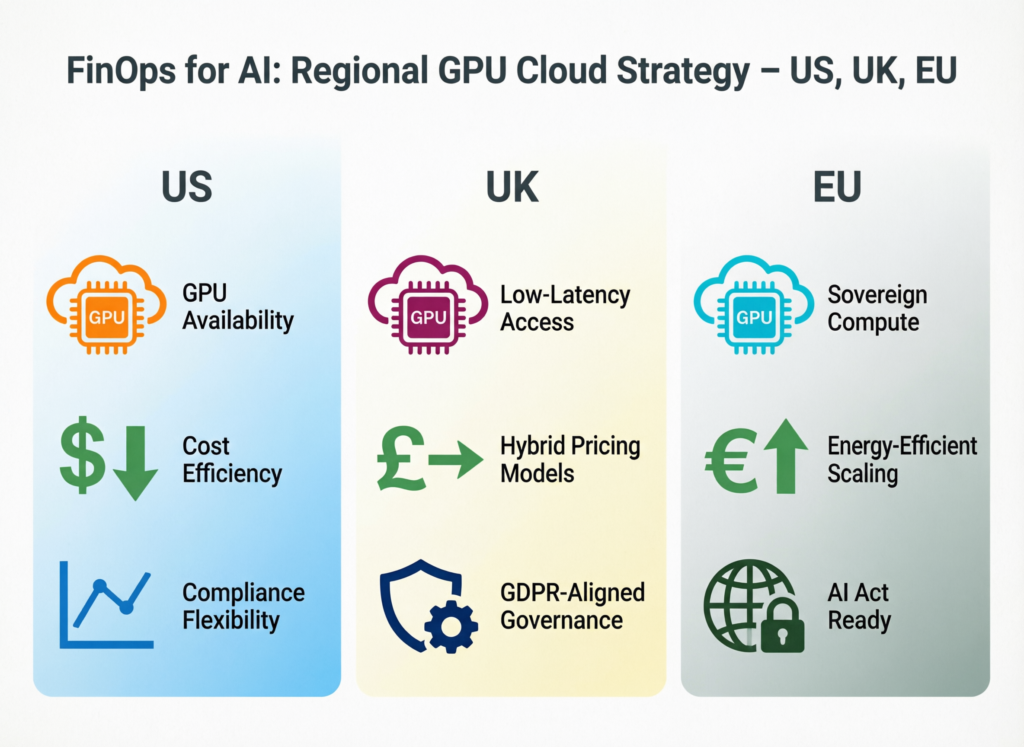
US, UK and Germany/EU AI FinOps Patterns
US SaaS and Enterprise Patterns
In the United States, fast-growing SaaS and enterprise AI teams (think New York or the Bay Area) typically:
Lean heavily on AWS, Azure and Google Cloud GPUs and managed AI APIs
Face high inference volumes and aggressive product roadmaps
Leverage enterprise commitments, reserved capacity and internal FinOps/AI centers of excellence to keep unit economics on track
Here, FinOps for AI often plugs into existing cloud cost programs and revenue operations to prove AI payback.
UK Fintech and Healthcare Under UK-GDPR and NHS Data Requirements
In the UK, London-centric fintechs and healthcare AI companies.
Run GPU workloads under UK-GDPR, FCA or PRA rules and NHS data standards
Put data residency, pseudonymisation and encryption front and center
Need airtight trails from GPU costs → model runs → regulated business processes
Their FinOps for AI dashboards often highlight region distribution, data residency flags and compliance-driven overheads, not just raw spend.
German and EU AI Teams Under BaFin, DSGVO and EU AI Act
German and EU AI teams under BaFin or other national regulators.
Prefer EU regions (Frankfurt, Dublin, Paris, Amsterdam) or EU-native GPU clouds like Genesis Cloud for sovereignty reasons.
Carefully model cross-border movement to and from the US or UK.
Often explore fixed-cost or bare-metal setups (including OpenMetal) for predictable budgets in long-running AI programs.
FinOps for AI becomes part of their regulatory story: proving control, predictability and a handle on systemic risk.
Tools and Platforms for FinOps for AI
Best FinOps Tools for AI Workloads
A growing ecosystem of platforms is adding AI/GPU-aware features:
CloudZero
Deep unit economics and AI-aware cost analytics for AWS, Kubernetes and AI platforms.
Ternary
Multi-cloud FinOps with AI cost management, anomaly detection and forecasting.
Flexera and other ITAM/SaaS tools
Useful where software licensing and SaaS usage blend with AI infra spend.
Most integrate with cloud billing, MLOps platforms and experimentation tracking so you can pipe cost per job, per token, per experiment into your FinOps reports.
GPU Cost Optimization Tools and Observability
On the observability side, you’ll see.
GPU utilization dashboards (per node, per pod, per job)
Job-level metering integrated with ML experiment trackers
Right-sizing recommendations and “hotspot” alerts
These feed into FinOps reports that finally make gpu utilization monitoring and reporting actionable rather than just “a nice chart in Grafana”.
Fixed-Price GPU Clouds vs Hyperscalers for FinOps Teams
Hyperscalers excel at flexibility and managed services but their GPU pricing can be volatile and complex. EU-focused GPU clouds like Genesis Cloud and private/bare-metal providers like OpenMetal offer more predictable, often lower, price points with trade-offs in ecosystem breadth.
From a FinOps perspective, the question is: where does predictability beat flexibility? Long-running training programs in a German bank might suit fixed-price or reserved options, while a startup experimenting with models in London needs hyperscaler agility.
Designing an AI FinOps Dashboard Engineers Actually Use
An AI FinOps dashboard that engineers in New York, London or Berlin actually open might include:
Real-time GPU spend by environment (dev/stage/prod)
GPU utilization and idle capacity
Cost per experiment, per model and per 1,000 queries
Team or product breakdowns and anomaly alerts posted to Slack or Microsoft Teams
Here’s where a BI layer matters; Mak It Solutions’ business intelligence services can help design dashboards that sit on top of your FinOps or observability data, not replace it.
Getting Started With FinOps for AI in Your Organization
30–60–90 Day Roadmap for AI FinOps
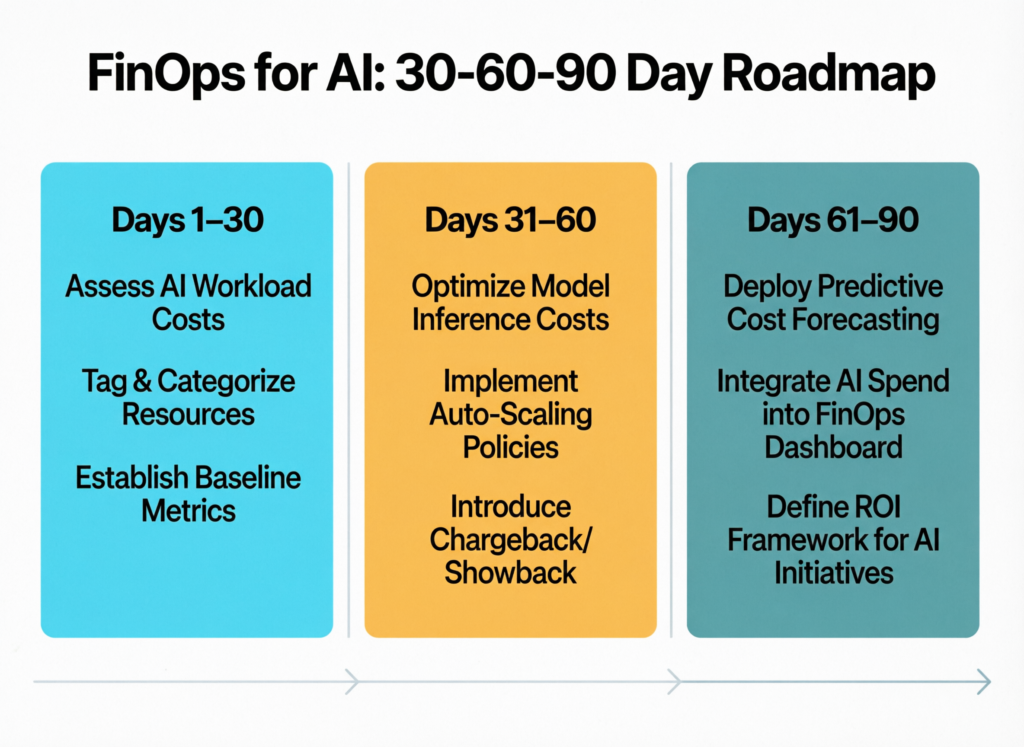
You don’t need a massive transformation to begin. A simple 30–60–90-day plan is enough to stand up a first version of FinOps for AI.
Days 0–30
Inventory AI workloads, map all GPU-related accounts, turn on basic tagging and create a rough baseline of training vs inference spend.
Days 31–60
Launch one pilot: maybe a key AI product in a US or UK region. Implement dashboards, budgets and alerts; run two or three optimization sprints on idle GPUs, right-sizing and experiment hygiene.
Days 61–90
Add governance: chargeback/showback models, simple forecasting and a monthly AI FinOps review with engineering and finance.
This is your minimum viable FinOps for AI operating model.
Roles, RACI and Operating Cadence
Successful teams clarify.
FinOps Owns methodology, dashboards and facilitation.
Platform/MLOps Owns implementation in Kubernetes, data platforms and CI/CD.
ML engineers and data scientists Own usage and local optimization.
Product and finance Own commercial decisions and pricing.
Many Mak It Solutions clients already use similar RACIs for cloud and DevOps in the US, UK and Europe; FinOps for AI extends that pattern to GPU and model costs.
When to Bring in External FinOps for AI Experts
You’ll know you’ve outgrown ad-hoc efforts when.
You’re running multi-region AI across US, UK and EU.
Compliance teams keep raising EU AI Act or data residency questions.
Your AI invoices are growing faster than revenue, and no one can explain why.
At that point, bringing in external FinOps for AI partners consultants, platforms or managed services can accelerate maturity. Firms like Mak It Solutions, with experience in cloud cost optimization, multi-cloud strategy and AI data privacy, can help you move faster without losing control.
Key Takeaways
FinOps for AI focuses on GPU-heavy workloads, using metrics like cost per token and cost per experiment to keep AI economics sustainable.
The biggest cost drivers are GPU type, region, training duration and hidden infra costs (storage, egress, logging and compliance), especially under GDPR, UK-GDPR and the EU AI Act.
Practical levers include right-sizing, scheduling, model optimization and experiment hygiene, supported by GPU-aware monitoring and FinOps dashboards.
Governance matters: chargeback/showback, forecasting and compliance-aware design keep AI spend aligned with business value and regulatory expectations.
Different regions US, UK, Germany/EU need tailored playbooks that reflect local regulations, preferred providers and data sovereignty requirements.
Tools like CloudZero, Ternary, Flexera, Genesis Cloud and OpenMetal, plus solid BI and analytics, give FinOps for AI teams the visibility and control they need.
If your GPU bills are growing faster than your AI revenue, now is the time to put a proper FinOps for AI playbook in place. Mak It Solutions can help you baseline AI infrastructure costs, design GPU-aware dashboards and align your architecture with regulations across the US, UK, Germany and wider Europe.
Reach out to our team to book a FinOps for AI discovery call, or explore our cloud cost optimization and multi-cloud strategy guides to start shaping your roadmap.( Click Here’s )
FAQs
Q : How do I calculate cost per token or cost per model query for my AI product?
A : Start by collecting total inference spend (GPU, managed LLM APIs, networking and observability) for a given period. Divide that by the total tokens or queries served in the same period, ideally broken down by product, customer segment or feature. Many teams in the US, UK and EU use proxies such as API calls or billable events when exact tokens aren’t available, then refine over time as they integrate deeper with model providers and MLOps tools.
Q : Should AI teams use spot GPUs, reserved instances, or fixed-price GPU clouds for training workloads?
A : It’s rarely either/or it’s a portfolio decision. For experimental training, spot or preemptible GPUs on AWS, Azure or Google Cloud can deliver big savings if your pipelines handle interruption. For steady, long-running programs, reserved instances or savings plans often make sense. In EU or highly regulated contexts, fixed-price GPU clouds or private/bare-metal options (e.g., Genesis Cloud, OpenMetal) can add predictability and sovereignty, at the cost of some managed services and flexibility.
Q : How can we allocate shared GPU cluster costs fairly across multiple AI teams and products?
A : The key is to choose fair, explainable allocation keys and apply them consistently. Popular approaches include allocating by GPU hours, tokens processed, jobs or experiments run, or a hybrid model (for example, 50% by GPU hours, 50% by token volume). Many organizations start with showback (visibility only), then move to chargeback once stakeholders in engineering, product and finance agree the model reflects reality across US, UK and EU teams.
Q : What FinOps dashboards and reports matter most for executives tracking AI investments?
A : Executives don’t need per-pod metrics they need unit economics and trends. Useful views include: total AI spend vs revenue, cost per 1,000 queries by product, GPU spend by region (US vs UK vs EU), and a pipeline of optimization opportunities with estimated savings. Combining FinOps for AI data with BI tooling lets leaders in New York, London or Berlin see whether AI projects deliver the promised ROI and where governance or architecture needs attention.
Q : How does FinOps for AI relate to broader MLOps and platform engineering practices?
A : FinOps for AI doesn’t replace MLOps or platform engineering it plugs into them. MLOps owns the lifecycle of models, data and deployment; platform teams own infrastructure and reliability; FinOps for AI adds financial visibility and decision-making to that stack. When they work together, every change to an AI pipeline new model size, new region, new feature comes with an upfront view of cost, risk and expected value.