
Disaster Recovery Architecture: Practical Cloud Patterns
Disaster Recovery Architecture: Practical Cloud Patterns

Disaster Recovery Architecture: Practical Cloud Patterns
Disaster recovery architecture is the end-to-end technical design for how your systems fail, recover and meet business continuity targets not just where backups are stored. It maps applications, data, networks and identity across regions and clouds so you can hit agreed RTO/RPO while staying compliant and within budget.
Introduction
Disaster recovery architecture is the end-to-end design for how your systems fail, recover and meet business continuity targets, far beyond “we have backups somewhere.” It defines how applications, data, networks and identities behave when a region, data center or SaaS dependency disappears. For modern teams in the United States, United Kingdom, Germany and the wider European Union (EU), a robust disaster recovery architecture is now table stakes for uptime, trust and compliance.
Industry studies suggest hourly downtime often falls in the $300,000–$1,000,000+ range for mid-to-large enterprises, depending on sector and scale. When you combine that with rising ransomware frequency and stricter regulations, “just backups” is no longer defensible to your board or regulators.
Outages, Ransomware and Regional Failures in 2025
IT outages are no longer rare “once a decade” events. Research in the UK and Ireland has found that over a quarter of firms suffer high-impact IT outages every week, with estimated costs between $1–3 million per hour. Meanwhile, global ransomware incident counts and victim numbers have climbed sharply since 2022, with thousands of organizations impacted each year.
Cloud helps, but it doesn’t eliminate risk: a misconfigured security group in Virginia or a DNS issue impacting an edge POP in Oregon can still bring down users in New York, London or Berlin. That’s why you need an architecture that assumes failure, not a hope that “our region never goes down.”
Disaster Recovery Architecture vs “Just Backups”
Backups answer “can I eventually get my data back?” Disaster recovery architecture answers “how quickly can I serve customers again, from where, with which data, and who is allowed to access it?”
Key differences
Backups
Copies of data (often offline or cold), restore is manual and slow.
DR architecture
Pre-defined regions, replication flows, failover mechanisms, runbooks, testing cadence and monitoring aligned to business impact.
You can have petabytes of backups and still fail an audit or spend days rebuilding production because nobody has designed the end-to-end path from outage to recovery.
How RTO, RPO and BCDR Fit Together
Recovery Time Objective (RTO) is how long an application can be down; Recovery Point Objective (RPO) is how much data loss (in time) the business can tolerate. Business continuity and disaster recovery (BCDR) translates those targets into concrete technical and process designs: patterns, tools, playbooks and tests.
A modern disaster recovery architecture explicitly maps each critical workload to:
Target RTO and RPO
Chosen DR pattern (backup & restore, pilot light, warm standby, active-active)
Responsible teams and automated runbooks
Without that mapping, you’re guessing.
What Is a Disaster Recovery Architecture?
A disaster recovery architecture is the technical blueprint for how your applications, data and infrastructure are replicated, failed over and restored to meet agreed RTO and RPO. It describes where each component runs, how state is protected and what happens at every layer when something breaks.
For a fintech in Frankfurt, that blueprint might describe cross-region replication between EU regions and tokenization services in a separate provider. For a healthcare analytics vendor serving the National Health Service (NHS), it may include UK-only regions, strict encryption and tightly controlled third-party access.
Key Building Blocks.
Think of your disaster recovery architecture in four layers.
Workloads
Apps, microservices, containers, functions.
Data
Databases, object storage, caches, logs, backups.
Network & Edge
VPCs/VNets, load balancers, DNS, CDNs.
Identity & Access
IAM roles, SSO, keys, secrets.
Each layer needs a recovery story. Active-active multi-region architecture at the app layer is useless if your identity provider is single-region or your CI/CD system can’t push to the secondary.
High Availability vs Disaster Recovery: What’s the Difference?
High availability (HA) keeps services running through small, local failures: instance crashes, AZ issues, rolling upgrades. Disaster recovery handles large, regional or systemic failures: whole-region outages, major ransomware, catastrophic misconfiguration.
HA is usually intra-region, focused on redundancy.
DR is cross-region or cross-cloud, focused on recovery and continuity.
Teams often assume that “we deployed across three AZs, so we’re safe.” That’s HA, not a full disaster recovery architecture.
Mapping RTO and RPO to the Business
RTO/RPO targets should not come from a whiteboard alone. Work with finance, operations and compliance to estimate:
Lost revenue per hour of downtime
Regulatory breach impact (e.g., GDPR fines, PCI non-compliance)
Reputational and contractual penalties
Studies suggest that for many enterprises, downtime can average over $500k per hour when you include lost revenue and remediation costs. Use those numbers to justify where you need active-active and where backup & restore is enough.
Core Disaster Recovery Architecture Patterns and Trade-Offs
At a high level, the main cloud disaster recovery architecture patterns are: backup & restore (cheapest, slowest), pilot light (minimal core always on), warm standby (scaled-down full stack) and multi-site active-active (highest cost, near-zero RTO/RPO)
Backup & Restore Pattern
Backup & restore suits non-critical systems where hours of downtime and data loss are acceptable: internal reporting, dev/test, batch analytics.
Typical characteristics
RTO: Many hours to days (restore + validation).
RPO: Hours, depending on backup frequency.
Cost: Lowest – mainly storage and occasional restore tests.
Risks: Backup corruption, untested scripts, slow large-scale restores.
For US-based SMEs in Austin or San Francisco this can be fine for back-office systems, but it’s rarely acceptable for customer-facing SaaS.
Pilot Light and Warm Standby Patterns
Pilot light keeps a minimal, critical subset of your infrastructure always running in a secondary region (for example, database replicas and core services), with the rest recreated on demand.
Warm standby keeps a full copy of the stack always on, but scaled down (for example, a single replica of each service and a smaller database cluster)
Typical ranges.
Pilot light
RTO in tens of minutes to a few hours, RPO in minutes to an hour, moderate cost.
Warm standby
RTO in minutes, RPO in seconds to minutes, higher ongoing compute cost.
For a London-based payments gateway or New York–based B2B SaaS platform, warm standby is often the sweet spot between risk and spend.
Multi-Site Active-Active Architectures
Active-active multi-region architecture runs production in two or more regions simultaneously and uses global routing (DNS, anycast, global load balancers) to distribute load.
Key design points:
Data consistency
Can you tolerate eventual consistency between Dublin and Amsterdam, or do you need strongly consistent databases?
Traffic management
Health checks, latency-based routing, failover policies.
Split-brain risk
Avoid scenarios where both sides process conflicting “truth” during partial outages.
This pattern is common for global SaaS platforms and digital banks in Frankfurt or London that require sub-minute RTO and near-zero RPO, but it demands careful engineering and disciplined operations.
Designing Cloud Disaster Recovery Architecture
Design cloud disaster recovery by selecting regions, replication methods and failover patterns that achieve your RTO/RPO while staying within budget and compliance constraints.
Shared Cloud DR Design Principles Across AWS, Azure and GCP
Across Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform (GCP), the core principles are similar:
Region & AZ choices
Start with paired or nearby regions (e.g., us-east-1 ↔ us-west-2, UK South ↔ UK West) and distribute components across availability zones.
Cross-region replication
Use managed database replication, object storage replication and log shipping for low RPO.
Automated failover
Combine health-checked global load balancing with automated DNS or front door failover.
Mak It Solutions’ recent guides on multi-cloud strategy and GCC sovereign cloud and data residency show the same patterns emerging across regions: start simple, then add complexity only when justified.
Reference Patterns on AWS, Azure and GCP
On AWS, the official DR whitepaper outlines four core strategies backup & restore, pilot light, warm standby, multi-site active-active – with concrete combinations of services like Amazon RDS, S3, Route 53 and CloudFormation.
On Azure, paired regions and services like Azure Site Recovery, Front Door and Traffic Manager underpin common setups for UK and EU workloads.
On GCP, patterns for North America and Europe often combine regional GKE clusters, multi-region Cloud Spanner or dual-regional Cloud SQL, and Cloud DNS for global failover.
If you’re comparing providers, Mak It Solutions’ AWS vs Azure vs Google Cloud comparison is a useful companion, especially when you’re deciding where to anchor regulated workloads.
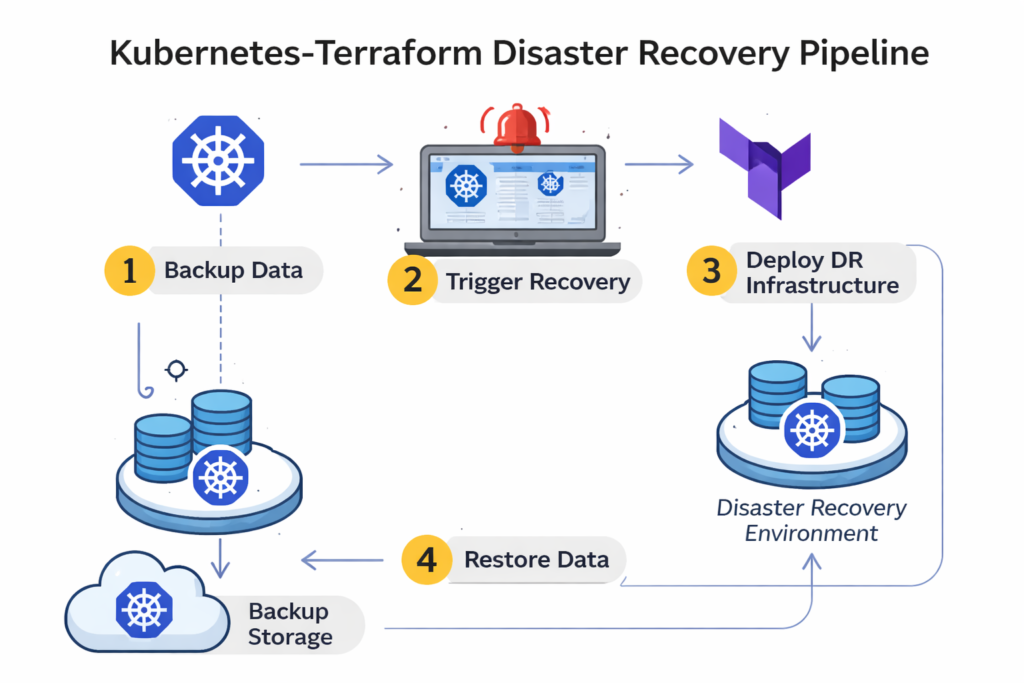
Kubernetes and Terraform Disaster Recovery Patterns
For Kubernetes-based stacks:
Run clusters in multiple regions for critical services, or maintain the ability to recreate clusters from GitOps and infrastructure-as-code (IaC)
Back up etcd consistently and encrypt snapshots.
Store manifests, Helm charts and secrets management configurations centrally.
For Terraform
Treat disaster recovery architecture as code – secondary regions, failover DNS records, health checks and runbooks should all live in version-controlled Terraform modules.
Automate DR tests via pipelines that simulate region loss and validate failover.
Mak It Solutions often combines Kubernetes, Terraform and managed backup platforms like Commvault or native snapshots for clients needing repeatable, auditor-friendly recovery processes across US, UK and EU regions.
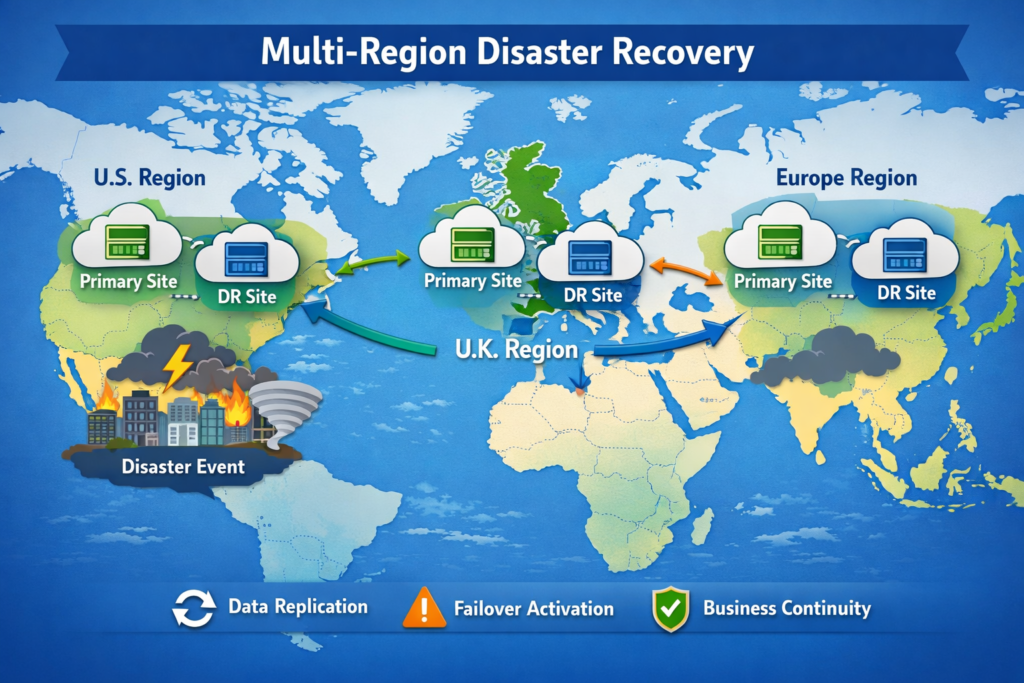
Multi-Region Disaster Recovery for US, UK and Europe
Multi-region disaster recovery balances latency, cost and regulatory data residency by pairing regions that are close enough for performance but safely located within allowed jurisdictions for replication.
US Region Pairing Examples and Patterns
In the US, a common pattern is pairing a primary in us-east-1 (Northern Virginia) with a secondary in us-west-2 (Oregon) using asynchronous replication and health-checked DNS failover. This works well for SaaS providers serving customers from New York to San Francisco.
Typical examples
Fintech Active-active APIs, warm-standby back-office systems.
Healthcare analytics HIPAA-aligned storage with encrypted cross-region backups.
B2B SaaS Warm standby for the control plane, backup & restore for internal tools.
Mak It Solutions’ article on cloud repatriation for US & Europe explores when some of these workloads might even move partly on-prem while keeping cloud-based DR.
UK and Ireland: London-Centric Region Designs
In the UK, Azure’s UK South ↔ UK West paired regions and London-aligned regions on other clouds are a natural foundation for open banking and NHS-aligned workloads.
A common pattern:
Primary services in London (e.g., UK South), with encrypted replication to a secondary UK region.
For some use cases, adding a tertiary EU region, such as Dublin, can support pan-EU customers while respecting UK-GDPR and sector-specific rules.
Germany and EU.
For German banks and insurers, Frankfurt is often the primary region due to data residency expectations and proximity to BaFin and ECB oversight.
Patterns include.
Primary in Frankfurt with intra-EU replication to Amsterdam or other EU regions.
Strict encryption, key management and logging to demonstrate DSGVO-konforme disaster recovery architektur.
Mak It Solutions’ work on cloud disaster recovery in GCC reflects similar thinking: anchor in the jurisdiction regulators expect, and replicate only to legally compatible regions.
Compliance-Driven Disaster Recovery Architectures
Compliance-ready disaster recovery architectures prove that you can recover within defined RTO/RPO while keeping regulated data in approved jurisdictions and with full auditability.
GDPR / DSGVO and UK-GDPR: Data Residency and Cross-Border Replication
GDPR and its UK equivalent require you to know where personal data lives, where it’s replicated and on what legal basis you transfer it.
Design implications.
Keep EU residents’ data within the EU unless you have an approved transfer mechanism.
Document which regions hold production data and backups.
Make DR tests part of your DPIA and records of processing.
Logs from failover tests, restore drills and incident simulations become crucial evidence if EU regulators ask you to prove your business continuity and disaster recovery controls.

HIPAA and PCI DSS Requirements for Cloud DR
HIPAA’s Security Rule emphasizes confidentiality, integrity and availability of ePHI, including requirements for backed-up copies and timely restoration.
For US hospitals or health-tech vendors:
Keep DR regions within the US.
Encrypt ePHI at rest and in transit, including backups.
Prove you can restore critical systems within a defined timeframe (for example, 72 hours)
PCI DSS v4.0 strengthens expectations for protecting cardholder data, continuous monitoring and secure configurations all of which intersect with disaster recovery architecture. Payment processors in New York or London need DR designs that ensure card data remains protected, even during failover and restore.
SOC 2, BaFin and Sector-Specific DR Obligations
SOC 2 reports now routinely inspect disaster recovery controls: backup frequency, restore tests, failover design and evidence. German financial institutions supervised by BaFin expect clear mappings of DR to critical outsourced IT services, including cloud providers.
If you operate across Germany, France, Netherlands, Spain or Italy, your auditors will care more about evidence than vendor marketing. That’s where Mak It Solutions often helps clients aligning architecture patterns with SOC 2 controls, BaFin guidance and sector playbooks, then packaging that into clear documentation.
Choosing the Right Disaster Recovery Architecture for Your Organisation
Select a disaster recovery architecture by ranking applications by business criticality, mapping RTO/RPO, then choosing the lowest-cost pattern that meets those targets.
Prioritising Applications.
Start with a simple tiering model:
Tier 0 – Mission critical (e.g., core banking, clinical systems) → Often active-active or warm standby.
Tier 1 – Customer-facing (e-commerce, SaaS control planes) → Warm standby or well-tuned pilot light.
Tier 2 – Internal line-of-business → Pilot light or backup & restore.
Tier 3 – Batch, analytics, dev/test → Backup & restore.
Map each tier to specific patterns and cloud regions. Mak It Solutions’ cloud migration plans and multi-cloud strategy guides show how this tiering integrates into broader cloud roadmaps.
Cost vs Risk.
Quantify the cost of downtime using realistic ranges from studies (for example, hundreds of thousands of dollars per hour). Then:
Compare annualized DR spend (extra regions, storage, automation) vs expected avoided downtime.
Highlight regulatory risk reduction: avoiding GDPR, HIPAA or PCI-related penalties.
CFOs respond well to scenarios: “For our London payments platform, moving from backup-only to warm standby costs X per year, but reduces expected outage losses by 3–5×.”
Practical Next Steps.
To move from theory to reality
Inventory and tier applications Include dependencies like identity, CI/CD and observability.
Choose region pairs and patterns per tier.
Codify DR in Terraform/Kubernetes and CI/CD.
Write runbooks for failover, rollback and partial failure scenarios.
Run game-days and tests at least annually; fix gaps and repeat.
If you need a partner, Mak It Solutions can help you turn these steps into a concrete roadmap, similar to how we design automated ticket resolution architectures and cloud DR in GCC.
Real-World Examples and DR Reference Architectures
DR Architecture Examples for US, UK and German Enterprises
US fintech
Active-active APIs across us-east-1/us-west-2, warm standby for internal services, encrypted backups to a third region, plus offline immutable backups.
UK healthcare/NHS supplier
UK-only regions, segregated environments for clinical vs non-clinical data, regular restore drills witnessed by customer representatives.
German bank
Frankfurt-primary, Amsterdam-secondary, detailed DR playbooks aligned to BaFin expectations, with annual tests feeding into SOC 2 and internal audit.
Mak It Solutions’ cloud repatriation and Cloud Disaster Recovery GCC articles show similar patterns adapted to local regulators and sovereign cloud options.
Lessons from Hyperscalers and SaaS Leaders
Large technology companies and major SaaS platforms typically:
Assume every dependency can fail – including their own control planes.
Invest heavily in automated failover and chaos testing.
Treat DR as continuous engineering, not a one-off project.
Public DR guidance from AWS and Azure reflects this: multi-region, automated, tested.
Common Anti-Patterns and How to Avoid Them
Watch for
Untested backups
No restore tests, no confidence.
Single-region everything
Including identity, logs and CI/CD.
Manual-only failover
Runbooks that assume experts are awake, calm and available.
No RTO/RPO alignment
Every system treated the same, or none mapped to business impact.
If you see these in your environment, treat them as early warning signs – and prioritise fixing the recovery architecture before the next big outage or ransomware campaign forces the issue.
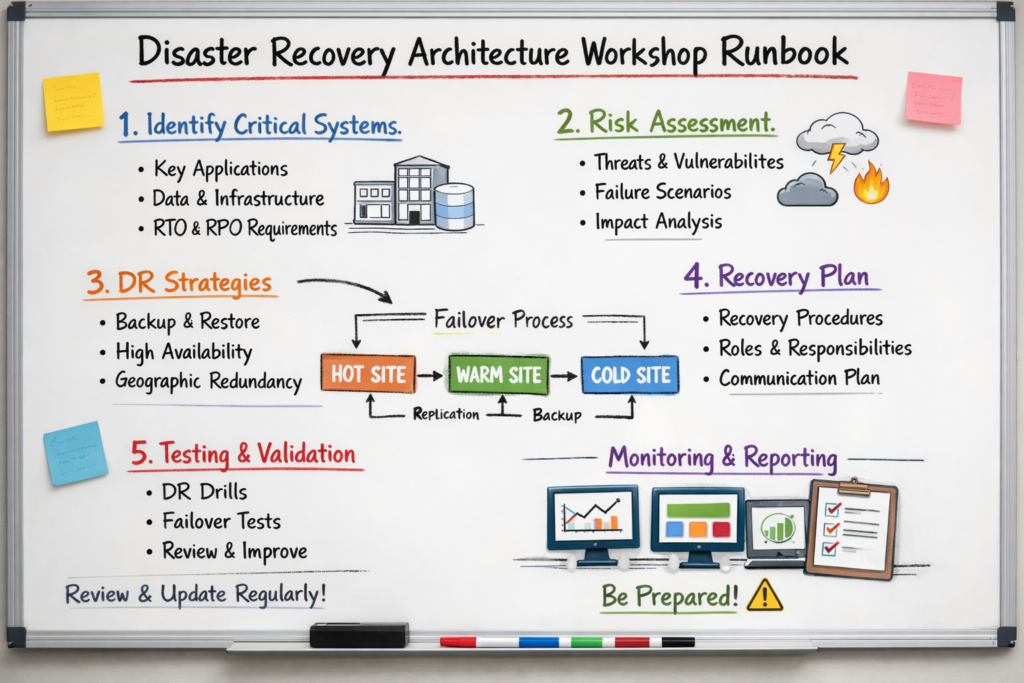
If you’re responsible for cloud platforms or critical applications in the US, UK or EU, this is the moment to move from “we have backups” to a tested disaster recovery architecture that your executives and auditors can trust.
Mak It Solutions works with CIOs, CTOs and architecture teams to design, implement and test cloud disaster recovery patterns across AWS, Azure and GCP – from pilot light to active-active multi-region designs.
If you’d like a practical review of your current setup and a scoped DR roadmap, get in touch via our services page and ask for a disaster recovery architecture workshop tailored to your region and regulatory landscape.
FAQs
Q : What are the four main types of disaster recovery and which one is best for a small enterprise?
A : The four common disaster recovery patterns are backup & restore, pilot light, warm standby and multi-site active-active. Small enterprises in the US, UK or EU usually start with backup & restore for non-critical systems and pilot light for their most important workloads, because those patterns keep costs manageable while still improving RTO/RPO. As revenue grows and regulatory pressure increases, stepping up to warm standby for core customer-facing services is often more cost-effective than living with long outages.
Q : How often should a disaster recovery architecture be tested and updated in the cloud?
A : At minimum, you should run a full disaster recovery test at least once per year and targeted component tests (such as database restores or DNS failover) every quarter. Cloud environments change quickly new services, regions and security recommendations appear every few months so your disaster recovery architecture should be reviewed whenever you make major application or infrastructure changes. Many regulated organizations in finance and healthcare adopt a rolling schedule of game-days, quarterly restore tests and an annual, fully documented DR exercise.
Q : Can I achieve multi-region disaster recovery without doubling my cloud spend?
A : Yes. You can design asymmetric multi-region architectures that protect critical services without mirroring everything one-to-one. Common techniques include using warm standby only for customer-facing components, keeping internal systems on backup & restore and scaling down secondary regions until failover is triggered. You can also use cost-optimized storage classes for backups, scheduled scaling for standby environments and automation so you only pay full capacity when it’s really needed. The goal is to match spend to risk – not to blindly duplicate every workload.
Q : How does disaster recovery architecture change when using Kubernetes and microservices?
A : With Kubernetes and microservices, disaster recovery architecture becomes more about cluster topology, stateful data and automation. Stateless services are relatively easy to redeploy in a new region using GitOps or CI/CD pipelines. The hard parts are stateful components (databases, queues, file stores) and cluster-level resources like ingress, certificates and secrets. Effective DR designs for Kubernetes typically involve multi-region or multi-cluster setups for critical services, regular etcd and database backups, and infrastructure-as-code so you can recreate entire clusters in minutes rather than days.
Q : What documentation and evidence do auditors expect for GDPR, HIPAA or PCI DSS disaster recovery compliance?
A : Auditors usually expect to see documented DR policies, architecture diagrams, RTO/RPO mappings, test plans and test results. For GDPR/DSGVO and UK-GDPR, they will focus on where personal data is stored and replicated, legal bases for cross-border transfers and how DR processes are captured in DPIAs and records of processing. For HIPAA and PCI DSS, they will look for clear backup and restore procedures, encryption controls, incident response plans and regular evidence that you can restore within required timeframes. Good documentation plus repeatable test results is often the difference between a smooth audit and a painful one.
[…] Cloud security misconfigurations are one of the fastest ways to turn a manageable cloud estate into a real business risk. In AWS, Azure, and Google Cloud, a single overly broad permission, public storage setting, or missing log source can expose sensitive data, weaken compliance posture, and slow down incident response. […]