

Domain LLM vs RAG: 2026 AI Decision Guide
Domain LLM vs RAG is really a choice between two AI strategies: connecting a model to trusted live knowledge, or adapting the model itself for a specific domain. Most enterprise teams should start with RAG when they need fresh, auditable, source-backed answers, then add fine-tuning or a domain-specific LLM when behavior, terminology, latency, or structured output quality needs to improve.
In practice, RAG helps the model “look things up” from approved sources. A domain LLM helps the model “think and respond” more like a specialist in your industry.
That difference matters for CTOs, AI leads, compliance teams, and product owners building production AI systems across the USA, UK, Germany, and the wider EU.
AI adoption is no longer experimental for many companies. McKinsey’s 2025 global survey reported that 88% of respondents said their organizations regularly used AI in at least one business function, but most were still working through the challenge of scaling AI beyond pilots.
So the real question is not, “Can we build a chatbot?”
It is: can the system cite the right policy, respect access rules, handle regulated data, and deliver consistent answers across teams in New York, London, Berlin, Munich, or anywhere else your business operates?
Domain LLM vs RAG: Core Difference
The core difference between a domain-specific LLM and RAG is where the system gets its strength.
RAG adds trusted external knowledge during the answer process. A domain LLM changes how the model behaves, understands terminology, follows patterns, or produces outputs.
| Option | Best For | Main Strength | Main Limitation |
|---|---|---|---|
| RAG | Fresh knowledge, citations, enterprise search | Retrieves current approved data | May still need prompting or tuning for consistent behavior |
| Domain LLM | Specialist language, tone, workflows | Better domain behavior and output patterns | Can become outdated without retrieval |
| Fine-tuning | Repeatable tasks and structured outputs | Improves consistency | Needs quality training examples |
| Hybrid RAG + Fine-tuning | Regulated, high-value workflows | Combines fresh knowledge with controlled behavior | More complex to govern and monitor |
What is RAG in enterprise AI?
Retrieval-augmented generation, or RAG, connects an LLM to approved knowledge sources such as SharePoint files, policy manuals, support tickets, product documentation, CRM records, clinical guidance, or internal databases.
The system retrieves relevant content, passes it to the model, and asks the model to answer using that context.
For example, a San Francisco SaaS company might use RAG so support agents can query release notes, product docs, and customer-specific contracts without retraining the model every week.
RAG is especially useful when the answer must be based on the latest approved document, not whatever the model learned during training.
What is a domain-specific LLM?
A domain-specific LLM is optimized for a particular industry, language, format, workflow, or expert task. It may be built through supervised fine-tuning, continued pretraining, instruction tuning, adapters, or a smaller specialized model.
A German manufacturing group in Stuttgart or Munich, for example, may need a model that understands technical maintenance reports, supplier language, multilingual documentation, and DSGVO-sensitive workflows more consistently.
RAG can provide the facts. A domain LLM can improve how those facts are interpreted and presented.
RAG vs LLM vs fine-tuning
An LLM is the base model. RAG is an architecture pattern around the model. Fine-tuning is a customization method used to change model behavior.
Use RAG when the knowledge changes often.
Use fine-tuning when the behavior needs to be consistent.
Use a domain LLM when the model must understand specialist language, workflows, and output formats at a deeper level.
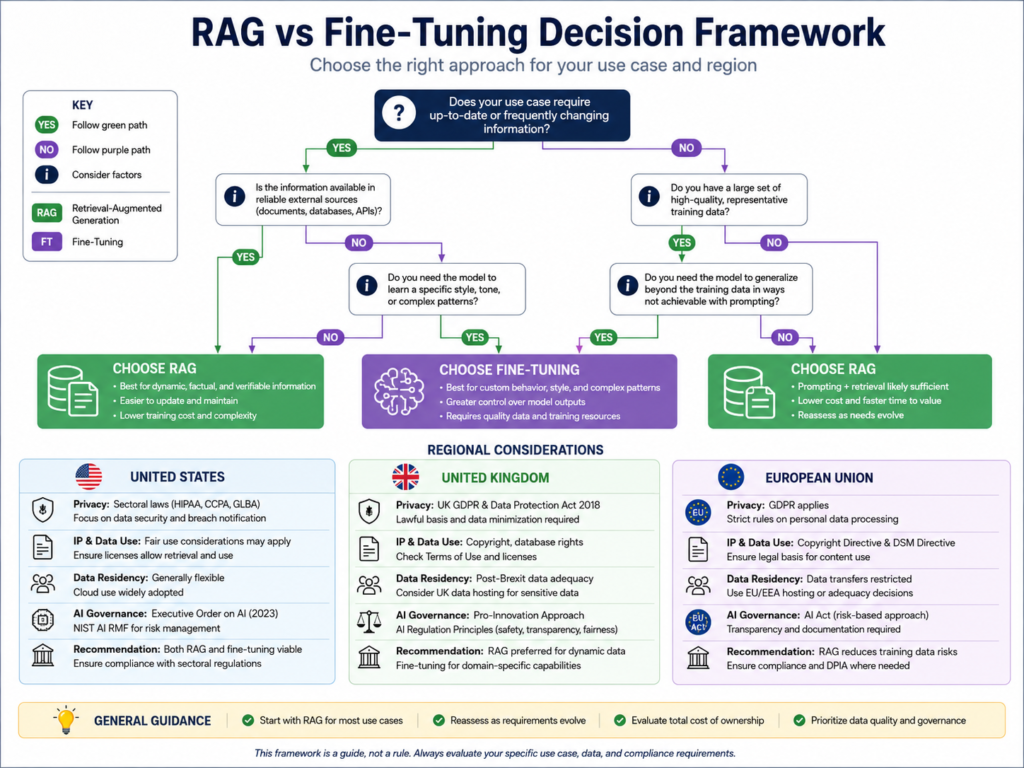
When to Use RAG Instead of a Domain LLM
Choose RAG when answers must be grounded in current company data, citations, access controls, and governed repositories.
For many enterprise teams, RAG is the safest first step because it improves freshness and traceability without immediately changing the model itself.
RAG for live knowledge bases, policies, and enterprise search
RAG works well for.
Internal knowledge search
HR policy assistants
Product-support copilots
Sales enablement tools
Customer service assistants
Compliance document search
Enterprise dashboards and portals
Instead of retraining every time a policy changes, the team updates the source repository and re-indexes the content.
That makes RAG useful for teams building customer portals, SaaS knowledge assistants, analytics dashboards, and enterprise workflow tools.
RAG for healthcare, finance, legal, and support assistants
In healthcare, RAG can help retrieve approved clinical protocols, payer guidance, or internal procedures while keeping access controls around sensitive information. In the USA, the HIPAA Security Rule sets standards for protecting electronic protected health information through administrative, physical, and technical safeguards.
In UK financial services, a London firm may use RAG to ground answers in FCA policies, Open Banking documentation, internal risk manuals, and customer communication rules.
In Germany and the EU, RAG can support GDPR, DSGVO, BaFin, and data residency planning by keeping retrieval permissions tied to approved repositories. The UK’s ICO also provides UK GDPR guidance for organizations handling personal data.
Why RAG can reduce retraining costs and improve auditability
RAG can reduce retraining costs because changing a document is usually cheaper than changing a model.
It also improves auditability because teams can log.
Retrieved sources
User permissions
Prompts
Model versions
Answer history
Human review decisions
Fallback cases
This is one reason RAG is attractive for regulated AI systems. Compliance teams can inspect what the system retrieved, who had access, and how the answer was generated.
When to Use a Domain-Specific LLM or Fine-Tuning
Fine-tuning or domain adaptation becomes useful when retrieval alone cannot teach the model how to behave.
RAG can bring in the right document, but it may not always produce the right tone, format, reasoning pattern, or classification label. That is where a domain LLM or fine-tuned model can help.
Domain adaptation for terminology, tone, and structured outputs
Domain adaptation helps when users expect the model to “speak the language” of the business.
A Boston healthcare AI assistant may need to distinguish patient intake language from billing codes. A Frankfurt banking assistant may need to use BaFin-aware terminology and structured risk categories. A legal operations model may need to summarize clauses in a consistent review format.
In these cases, RAG provides the information, while fine-tuning improves the response style and task pattern.
Fine-tuning for repeatable tasks and expert workflows
Fine-tuning is useful for repeatable workflows such as.
Ticket classification
Insurance claim summarization
Medical coding support
Contract clause extraction
Customer response drafting
Risk category labeling
Multilingual manufacturing documentation
Smaller fine-tuned models can also reduce latency when the task is narrow, high-volume, and well-defined.
For example, a field-service mobile app might use a fine-tuned model to classify maintenance notes quickly, while RAG retrieves the latest equipment manual only when needed.
Custom LLM training vs supervised fine-tuning
Full custom LLM training is expensive and rarely the first choice for most enterprises.
Supervised fine-tuning is more practical when you already have high-quality examples of desired inputs and outputs. Lightweight adaptation methods can also be useful when teams need targeted behavior changes without rebuilding the full model.
The decision should depend on.
Task value
Data quality
Compliance exposure
Latency needs
Usage volume
Evaluation requirements
Maintenance cost
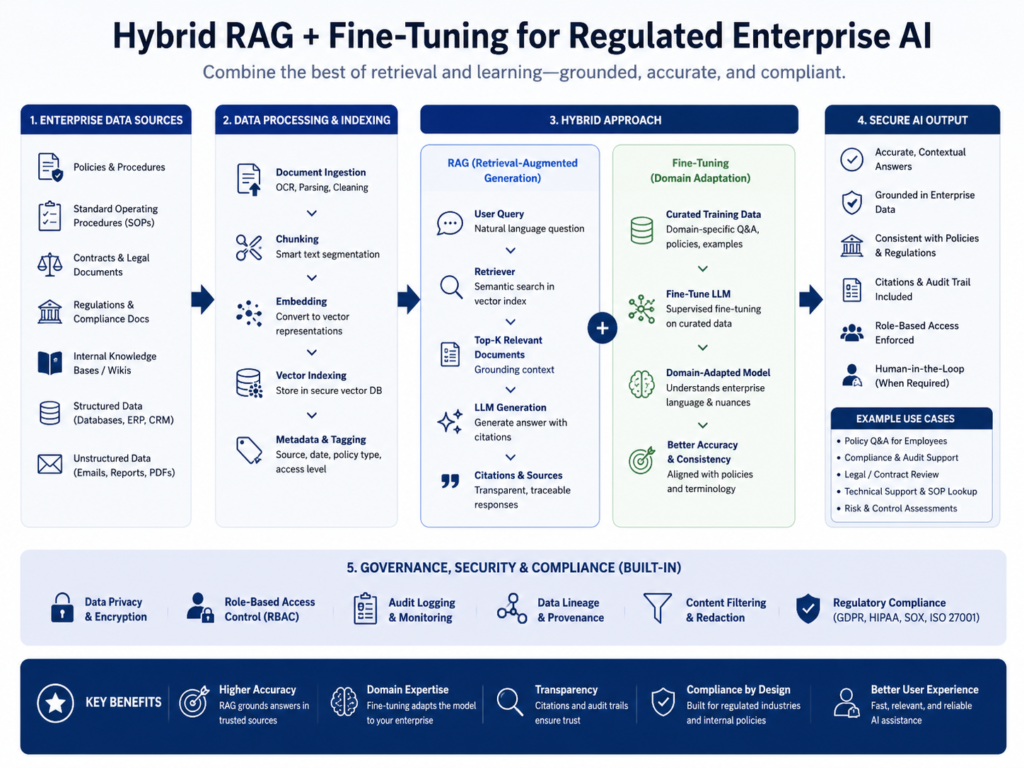
Hybrid RAG + Fine-Tuning Architecture
A hybrid architecture is often the strongest option for regulated enterprises.
RAG supplies governed information at runtime. Fine-tuning shapes how the model interprets, formats, and responds to that information.
When hybrid RAG beats either option alone
Hybrid RAG + fine-tuning is valuable when a system must cite current policies and produce consistent expert outputs.
For example, an NHS-facing assistant may retrieve current approved guidance through RAG while using fine-tuning to format escalation notes, patient-facing summaries, and clinician review prompts.
In enterprise support, hybrid systems can retrieve live product data while fine-tuning improves tone, structure, and response consistency.
RAG with a custom LLM for regulated enterprises
A regulated RAG architecture usually includes.
Identity management
Role-based access control
Approved document repositories
Vector databases
Audit logs
Human review queues
Evaluation sets
Content filters
Model monitoring
Incident response workflows
Cloud and AI infrastructure choices may include AWS, Amazon Bedrock, Microsoft Azure AI Foundry, Google Cloud Vertex AI, Databricks, IBM, or NVIDIA-based environments.
For sensitive workloads, teams should also evaluate confidential computing, encryption, private networking, retention policies, and vendor risk before sending regulated data through AI pipelines.
RAFT, Graph RAG, agentic RAG, and fine-tuned RAG
Several advanced RAG patterns are becoming more common in enterprise AI planning.
RAFT combines retrieval-aware training with fine-tuning so the model learns to use retrieved context more effectively.
Graph RAG uses knowledge graphs to improve relationships between entities, documents, people, assets, and business rules.
Agentic RAG lets AI systems plan retrieval steps, use tools, call APIs, and ask follow-up questions when the answer needs more context.
These patterns can be powerful, but they also increase governance requirements. The more autonomy the system has, the more important logging, testing, access control, and human oversight become.
USA, UK, Germany and EU Compliance Considerations
Regulated enterprises should not choose between RAG and domain LLMs based only on accuracy.
They should compare data residency, traceability, access controls, audit logs, retrieval permissions, model update cycles, procurement risk, and human review requirements.
USA.
In the USA, healthcare teams must treat AI systems around electronic protected health information carefully under HIPAA security expectations. HHS describes the HIPAA Security Rule as requiring safeguards to protect the confidentiality, integrity, and availability of ePHI.
Financial-services, SaaS, and e-commerce companies may also need SOC 2 controls, PCI DSS alignment for payment data, vendor risk reviews, encryption, and access logs. The PCI Security Standards Council describes PCI SSC as the global forum that develops and promotes payment data security standards.
A New York fintech or Seattle SaaS provider should design RAG permissions so the model cannot retrieve customer data beyond the user’s role.
UK.
In the UK, AI teams must consider UK GDPR, ICO expectations, NHS procurement standards, FCA oversight, and Open Banking security requirements.
A Manchester health tech team building an NHS-facing assistant should treat citations, review queues, and human-in-the-loop checkpoints as core product requirements, not optional add-ons.
For personal data, the ICO’s UK GDPR guidance remains an important reference point for organizations designing AI workflows.
Germany and EU.
In Germany and the EU, GDPR/DSGVO, BaFin expectations, works council concerns, multilingual retrieval quality, and EU data residency can shape the architecture.
A Berlin or Hamburg enterprise may prefer EU-hosted vector databases, EU cloud regions, stricter logging policies, and clear data retention controls for sensitive datasets.
The EU AI Act entered into force on 1 August 2024 and was planned to become fully applicable on 2 August 2026, with exceptions. The European Commission notes that the Act applies in phases, and teams should verify the live timeline because AI regulation continues to evolve.
As of May 2026, Reuters also reported that EU lawmakers had reached a provisional deal to delay enforcement of some high-risk AI rules, so regulated teams should confirm the final implementation status before launch.
Decision Framework: Which AI Architecture Should You Choose?
For most enterprise AI teams in 2026, the practical path is simple:
Start with RAG. Measure accuracy, governance, and user trust. Then add fine-tuning or a domain-specific LLM where retrieval alone does not solve behavior, latency, or workflow consistency.
Choose RAG if freshness and source traceability matter most
Choose RAG when.
Content changes often
Users need citations
Compliance teams need audit trails
Permissions matter
Source documents are the authority
The workflow depends on current policies or records
RAG is a strong fit for policy assistants, enterprise search, customer support, financial research, healthcare knowledge tools, and internal copilots.
Choose a domain LLM if behavior and terminology matter most
Choose a domain LLM or fine-tuned model when outputs must follow consistent formats, domain language, or specialized workflows.
This works well for legal drafting patterns, support triage, claims handling, clinical summaries, risk labeling, and multilingual manufacturing documentation.
Choose hybrid RAG + fine-tuning for regulated workflows
Choose hybrid architecture when the workflow is valuable, regulated, and repeatable.
In practice, this is often the best answer for enterprise AI in finance, healthcare, legal operations, insurance, industrial SaaS, and large internal knowledge systems.
By 2026, AI teams are under more pressure to prove measurable value, not just launch impressive demos. McKinsey’s 2025 survey found broad AI use, but also showed that many organizations were still moving from pilots to scaled impact.

Concluding Remarks
Domain LLM vs RAG is not a model popularity contest. It is a strategy choice about freshness, behavior, governance, cost, and business risk.
Use RAG when you need current, source-backed answers.
Use fine-tuning or a domain LLM when you need consistent behavior.
Use hybrid RAG + fine-tuning when you need both.
Before buying tools, map your data sources, user roles, compliance obligations, evaluation metrics, and production workflows. The best AI architecture is the one your business can trust, govern, measure, and improve. Mak it Solutions
Planning an enterprise AI system and unsure whether RAG, fine-tuning, or a domain-specific LLM fits best? Start with a scoped AI architecture assessment so your team can map data, compliance needs, and production roadmap before scaling. (Click Here’s )
Key Takeaways
RAG is usually the best first step when enterprise answers need current sources, citations, and access control.
A domain LLM or fine-tuned model is better when tone, terminology, structure, and repeatable behavior matter.
Hybrid RAG + fine-tuning is strongest for regulated, high-value workflows.
USA, UK, Germany, and EU teams should evaluate HIPAA, UK GDPR, GDPR/DSGVO, BaFin, PCI DSS, SOC 2, data residency, and auditability early.
Vendor choice should include cloud region availability, audit logging, evaluation tooling, vector database controls, and human review workflows.
AI architecture should be validated with real workflow metrics before enterprise-wide rollout.
FAQs
Q : Is RAG cheaper than fine-tuning for enterprise AI?
A : RAG is often cheaper to start because teams can connect existing documents, databases, and knowledge repositories without retraining the model. Costs still depend on document volume, vector database usage, cloud hosting, evaluation, and security controls. Fine-tuning can become cost-effective for narrow, high-volume tasks where consistent behavior and lower inference cost matter.
Q : Can RAG reduce hallucinations in regulated industries?
A : Yes, RAG can reduce hallucinations when it retrieves high-quality, approved sources and asks the model to answer from that context. It does not eliminate risk by itself. Regulated teams still need permission controls, source ranking, evaluation sets, human review, monitoring, and fallback behavior when the system lacks enough evidence.
Q : Does a domain-specific LLM need private company data?
A : Not always. A domain-specific LLM may be trained or adapted with public industry data, licensed datasets, synthetic examples, or carefully selected internal examples. Private company data is useful when the model must reflect proprietary workflows, terminology, or output formats. Sensitive data should be minimized, protected, and reviewed for compliance before training.
Q : What data should enterprises prepare before building RAG?
A : Enterprises should prepare clean, permissioned, up-to-date documents with clear ownership. Useful sources include policies, product documentation, support tickets, knowledge-base articles, contracts, SOPs, clinical guidance, and compliance manuals. Teams should also define metadata, access roles, retention rules, evaluation questions, and source-of-truth systems before implementation.
Q : Can RAG meet GDPR, DSGVO, HIPAA, or PCI DSS requirements?
A : RAG can support compliance, but it does not automatically make a system compliant. Teams must design access controls, encryption, audit logs, retention policies, vendor agreements, data residency, and human review into the architecture. For GDPR/DSGVO, HIPAA, and PCI DSS contexts, legal, security, and compliance teams should review the workflow before launch.