

Enterprise RAG: Patterns That Win
Enterprise RAG is no longer just a clever chatbot connected to company documents. In 2026, it is a serious enterprise AI architecture pattern for grounding large language model answers in approved business knowledge, with access control, citations, monitoring, and compliance built in.
At its best, enterprise RAG helps teams answer business questions faster without letting the model guess from memory. The system retrieves trusted company data first, applies permissions, sends only the right context to the LLM, and returns an answer users can verify.
That sounds simple. In practice, the hard part is everything around the model: messy documents, stale policies, complex permissions, latency, governance, and audit trails.
A New York fintech, a London public-sector supplier, and a Munich SAP-heavy manufacturer may all need RAG. But they should not deploy it with the same assumptions.
What Is Enterprise RAG?
Enterprise RAG stands for enterprise retrieval augmented generation. It combines retrieval systems, large language models, business data, governance controls, and application workflows so users can ask questions and receive grounded answers.
Instead of relying only on what an LLM already “knows,” the system searches trusted internal sources first. These may include SharePoint, Confluence, Salesforce, ServiceNow, SAP, Snowflake, Databricks, PDFs, contracts, policies, tickets, and databases.
For AI leaders, CTOs, CIO teams, and platform architects, enterprise RAG matters because private business knowledge changes constantly. Policies are updated. Contracts expire. Product details shift. Compliance requirements evolve.
RAG gives organizations a practical way to use generative AI while keeping answers tied to current, governed information.
Why Enterprise RAG Fails Without Architecture
Many RAG pilots look impressive in a boardroom. A few documents are uploaded, the chatbot answers friendly questions, and the demo feels like progress.
Then real users arrive.
They ask vague questions. They use internal abbreviations. They expect the assistant to know which policy is current. They ask about documents they are not allowed to access. They want fast answers with reliable citations.
This is where weak architecture breaks.
Production RAG succeeds when four areas work together.
Retrieval quality: Can the system find the right evidence?
Governance: Can it enforce permissions and source rules?
Evaluation: Can the team measure accuracy and usefulness?
Compliance: Can the system stand up to legal, security, and audit review?
The EU AI Act is described by the European Commission as the first legal framework on AI, while NIST’s AI Risk Management Framework is intended for voluntary use to improve trustworthy AI practices. These frameworks are useful reminders that production AI is not only a model problem; it is a risk-management problem too.
Enterprise RAG Architecture for Production Systems
A production enterprise RAG architecture usually includes.
Source systems
Data ingestion
Cleaning and chunking
Embeddings
Vector database or search index
Hybrid search
Reranking
Permission-aware retrieval
LLM orchestration
Citations
Observability
Governance workflows
The goal is not just to generate an answer. The goal is to generate an answer from the right evidence, for the right user, under the right controls.
Core Architecture Components
A strong enterprise RAG stack starts with approved source systems such as SharePoint, SAP, Snowflake, Databricks, Google Drive, internal databases, CRMs, ticketing systems, PDFs, and APIs.
The content is cleaned, split into useful chunks, enriched with metadata, embedded, indexed, and stored in a search layer or vector database. Common options include Redis, Pinecone, Weaviate, OpenSearch, PostgreSQL with pgvector, and cloud-native search tools.
The retrieval layer finds candidate evidence. The orchestration layer filters results, applies permissions, ranks sources, passes context to the LLM, and formats the answer with citations.
Governance sits across the whole system. It controls access, source approval, retention rules, audit logs, and escalation workflows.
For teams building custom AI portals, SaaS platforms, or dashboards, enterprise RAG can connect naturally with Mak It Solutions’ web development services, Node.js development services, and Python development services.
Cloud and Data Platform Patterns
Enterprise RAG can be built on AWS, Microsoft Azure, Google Cloud, Snowflake, Databricks, or hybrid infrastructure.
AWS teams may use S3, Bedrock, OpenSearch, and IAM. Azure teams may use Azure AI Search, Azure OpenAI, Microsoft Entra ID, and Purview. Google Cloud teams may connect Vertex AI, BigQuery, and enterprise search.
Snowflake and Databricks often matter in data-heavy companies because governed business data already lives there.
The right architecture depends on your current stack, compliance needs, internal skills, and data-residency requirements.
RAG Best Practices That Actually Work
The biggest RAG improvements usually come from better retrieval, not just a bigger model.
A powerful model with poor context will still produce weak answers. A smaller model with excellent retrieval, ranking, citations, and guardrails can often perform better in real business workflows.
Hybrid Search Beats Pure Semantic Search
Semantic search is good at matching meaning. Keyword search is better for exact terms, product codes, legal clauses, account IDs, policy names, and compliance language.
Hybrid search combines both.
That matters in enterprise environments. A healthcare team may need exact HIPAA policy language. An engineering team may need semantically similar incident reports. A banking team may need both exact FCA terminology and broader relationship matching.
Good retrieval also depends on chunking. Chunks should preserve headings, tables, timestamps, document hierarchy, ownership, and business context.
Bad chunks create bad answers.
Graph RAG Helps With Complex Relationships
Graph RAG connects documents, people, entities, systems, regulations, products, and workflows.
This is useful when the answer depends on relationships, not just passages.
For example, a Munich manufacturer may ask: “Which suppliers are affected by this EU compliance change, and which SAP modules store the relevant records?”
A simple vector search may miss the relationship. A knowledge graph RAG system can map suppliers, contracts, jurisdictions, systems, and controls together.
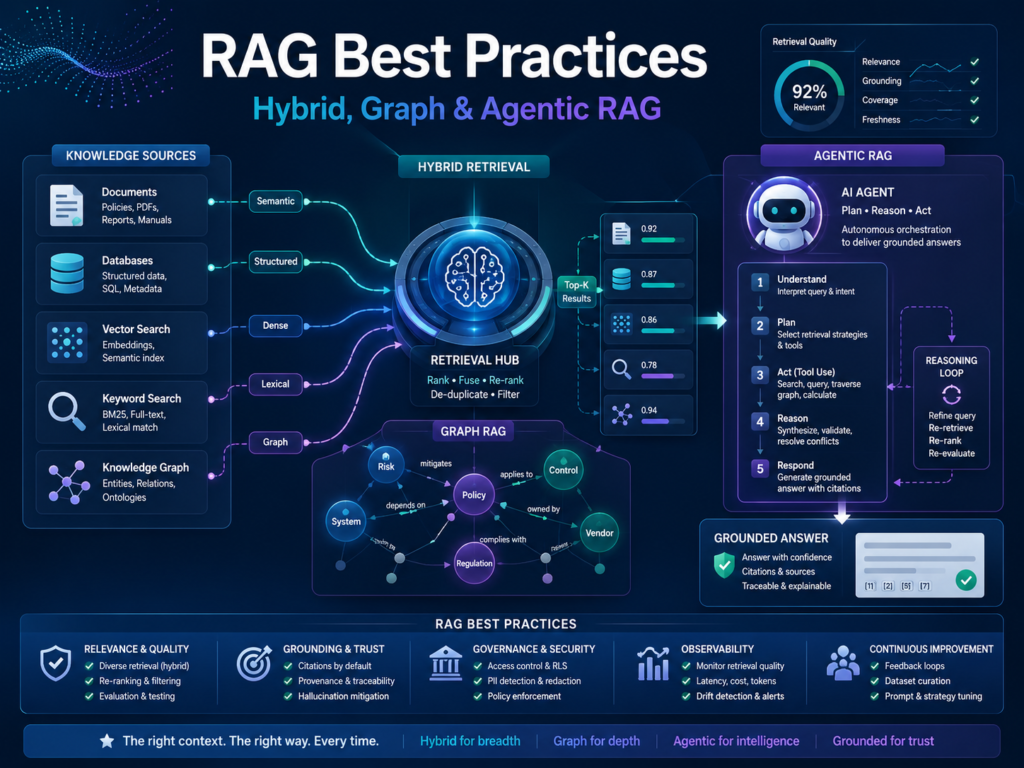
Agentic RAG Supports Multi-Step Workflows
Agentic RAG uses AI agents to plan, retrieve, verify, call tools, and complete multi-step tasks.
Corrective RAG adds another useful layer. It checks whether the retrieved evidence is strong enough. If not, it can retry, ask for clarification, or escalate to a human.
These patterns are useful for.
Support triage
Contract review
Policy lookup
Vulnerability analysis
Sales enablement
Data analytics
Internal knowledge management
Mak It Solutions’ Business Intelligence Services can support the reporting and KPI layer around enterprise AI adoption.
Common Enterprise RAG Failure Patterns
Most enterprise RAG failures do not happen because the model is “bad.”
They happen because the system around the model is unfinished.
The Naive RAG Trap
Naive RAG often means uploading documents, creating embeddings, and asking questions.
That can work for a demo. It rarely works at scale.
Production users expect correct citations, current sources, fast response times, and permission-aware answers. They also expect the system to say “I don’t know” when the evidence is missing.
The failure usually appears in stages. First, users enjoy the novelty. Then they notice weak citations. Then security or legal teams find access issues. Finally, business leaders lose trust because no one can explain quality, cost, or risk.
Bad Chunking, Stale Data, and Weak Permissions
Enterprise RAG breaks when documents are poorly prepared.
Common issues include.
Chunks that cut off important context
Duplicate or outdated documents
Weak metadata
Missing ownership
Poor ranking
No document expiry rules
Incomplete access controls
No answer evaluation process
Hallucination can still happen when the model receives irrelevant or incomplete context. RAG reduces risk, but it does not remove the need for testing, monitoring, and governance.
The real question is not only, “Did the model produce a nice answer?”
The better question is, “Did the system retrieve the right evidence for the right user at the right time?”
RAG Governance, Evaluation, and Observability
Enterprise RAG needs measurement. Without it, teams are guessing.
Evaluation and observability turn RAG from a black-box assistant into a managed AI platform.
How to Evaluate Enterprise RAG
Evaluation should test retrieval and generation separately.
Retrieval metrics may include.
Recall
Precision
Hit rate
Mean reciprocal rank
Citation relevance
Whether the top sources contain the answer
Generation metrics may include.
Factual accuracy
Citation support
Refusal quality
Tone
Usefulness
Safety
Completeness
Build a golden dataset from real employee questions. Include easy questions, edge cases, compliance questions, adversarial prompts, and questions the assistant should refuse.
Subject matter experts should review results before the system is expanded.
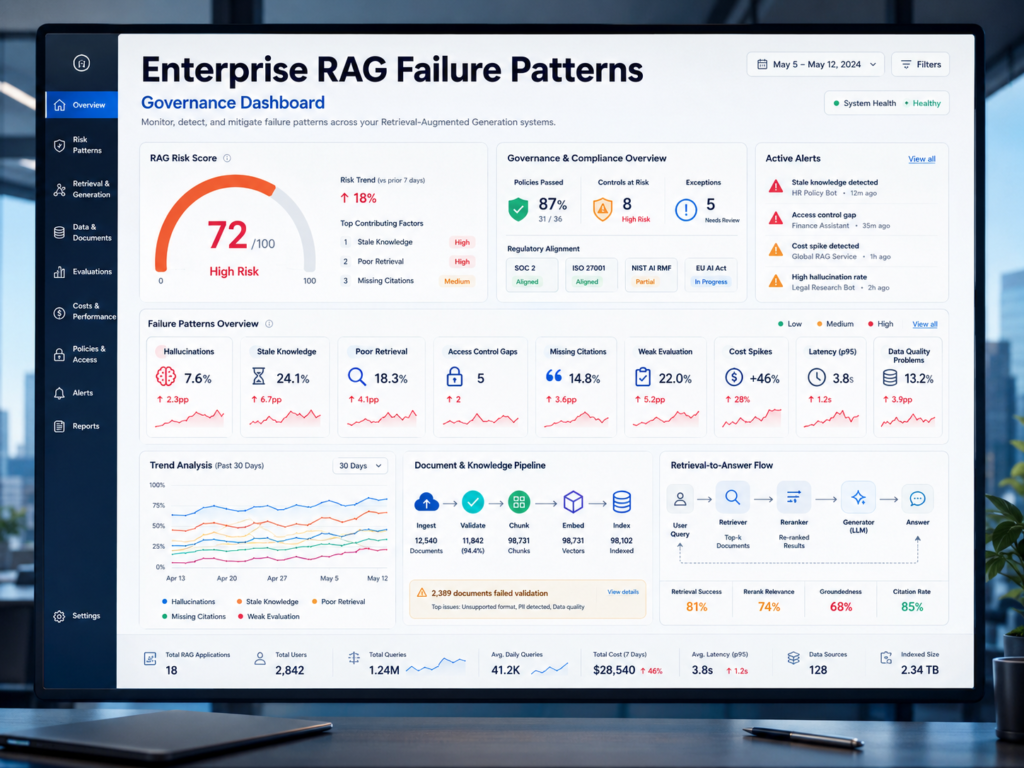
What RAG Observability Should Track
A good observability setup should capture.
User query
Retrieved chunks
Ranking scores
Prompt version
Model version
Generated answer
Citations
Latency
Cost
User feedback
This helps teams debug failures instead of guessing.
If a Manchester public-sector team gets poor answers, observability can show whether the issue came from missing documents, bad metadata, weak ranking, or model behavior.
Governance Controls for AI Leaders
RAG governance should include access control, source approval, content lifecycle management, audit logs, human escalation, evaluation gates, risk classification, and incident response.
Ownership also needs to be clear.
Data teams may own source quality. Platform teams may own infrastructure. Security may own permissions. Legal and compliance may define risk requirements. Business teams should approve answer quality.
Without clear ownership, RAG systems drift.
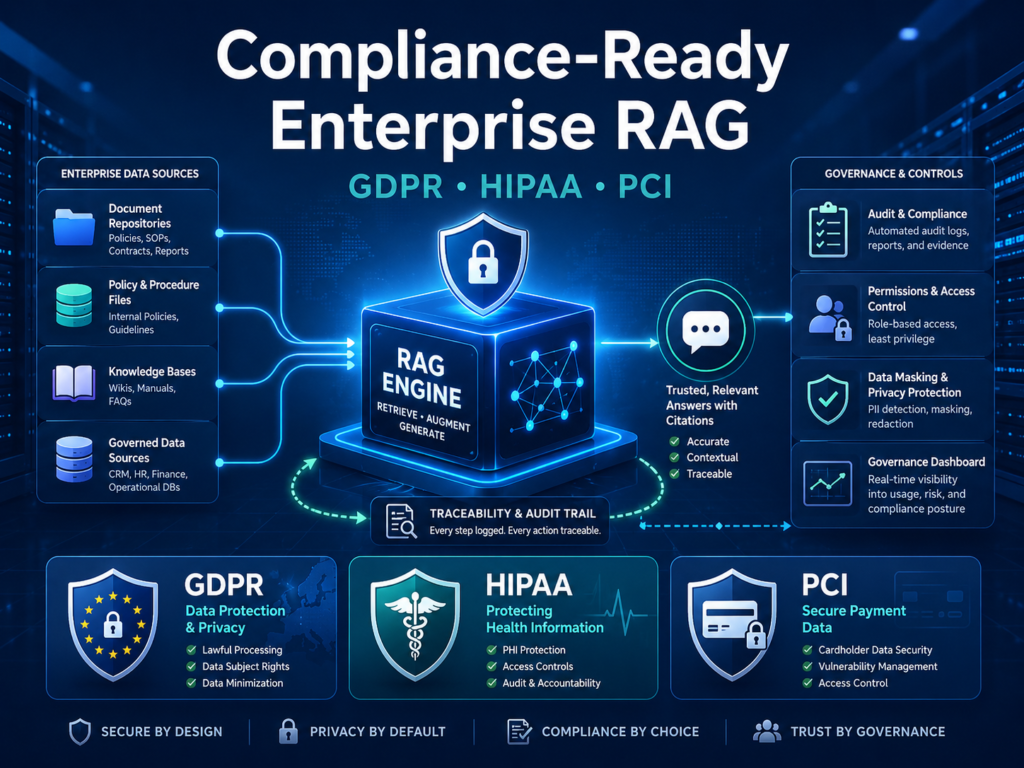
Compliance-Ready Enterprise RAG Across USA, UK, Germany, and EU
Compliance-ready RAG does not mean the model is magically compliant.
It means privacy, security, access control, logging, vendor review, data residency, and human oversight are designed into the system from the start.
USA.
In the USA, healthcare RAG may need HIPAA and HITECH safeguards for protected health information. HHS explains that the HIPAA Privacy Rule protects individually identifiable health information held or transmitted by covered entities or business associates.
A New York fintech may need SOC 2 controls, PCI DSS for payment data, FINRA and SEC retention rules, and strong vendor management. PCI DSS provides a baseline of technical and operational requirements designed to protect payment account data.
A Boston medical device company may also need FDA-aligned quality processes if AI supports regulated workflows.
UK.
In the UK, RAG projects should account for UK-GDPR, data protection impact assessments, NHS data governance, FCA and PRA expectations, Open Banking controls, and public-sector assurance.
A London bank building a policy assistant should carefully separate internal policy lookup from regulated customer advice.
A Manchester NHS supplier should avoid positioning RAG as an unsupervised clinical decision-maker. Safer use cases include procurement support, staff training, policy lookup, and internal knowledge management with human oversight.
Germany and EU.
Germany and the wider EU require close attention to GDPR, DSGVO, BaFin expectations, ISO 27001, data residency, and EU AI Act readiness.
A Berlin insurer, Frankfurt bank, Hamburg logistics group, or Munich manufacturer may need regional hosting, SAP integration, strict access control, documented audit trails, and clear vendor terms.
For EU teams, the safest approach is to classify the use case, map the data involved, document controls, and keep human oversight where the risk level requires it.
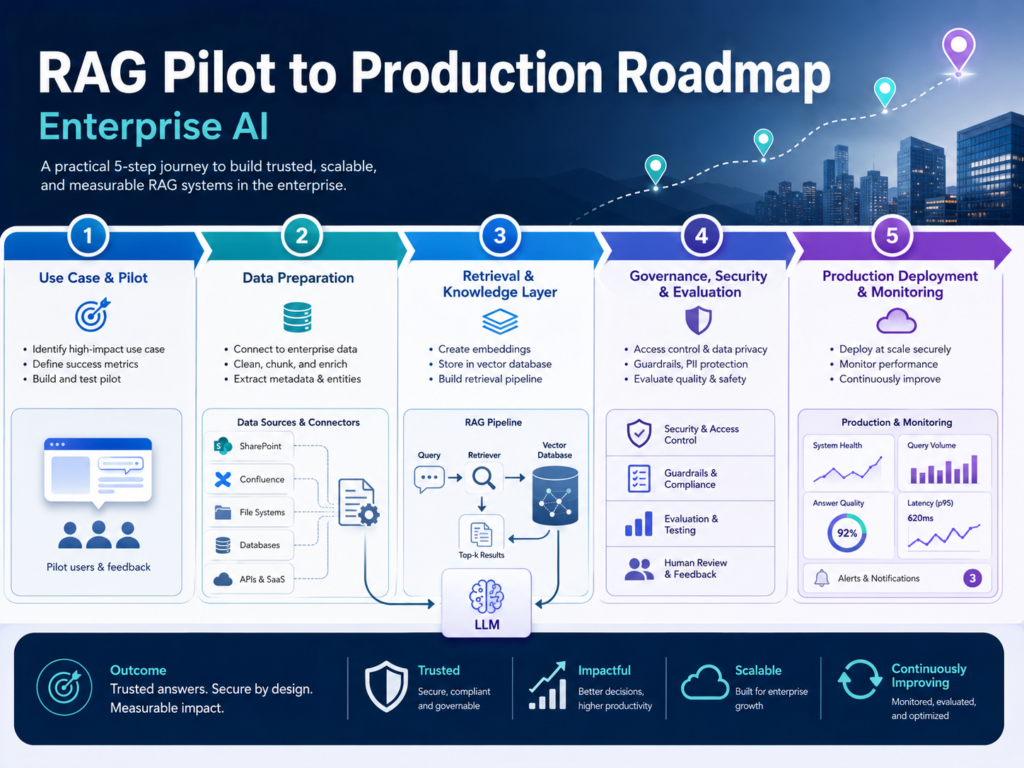
How to Move From RAG Pilot to Production
Moving from pilot to production requires a staged roadmap.
The goal is not to launch faster at any cost. The goal is to launch a system users can trust.
A Practical Production Roadmap
Start with a focused use case. Identify users, data sources, risk level, answer types, and success metrics.
Then prepare the data. Remove stale files, preserve metadata, define document owners, and set rules for refresh and expiry.
Next, design retrieval. Choose chunking patterns, hybrid search, reranking, metadata filters, and permission-aware retrieval.
After that, build evaluation. Create test questions, measure retrieval quality, review answer accuracy, and validate citations.
Finally, roll out in stages. Start with monitored users, collect feedback, improve retrieval, and expand only when quality and governance are stable.
Build vs Buy for Enterprise RAG
Use cloud-native RAG when your team already works deeply in AWS, Azure, or Google Cloud and wants faster integration.
Use managed AI platforms when speed, vendor support, and standard controls matter more than deep customization.
Choose custom architecture when your organization has complex permissions, legacy systems, multi-cloud requirements, SAP dependencies, strict data residency, or regulated workflows.
This is where Mak It Solutions can combine AI, cloud, web, SaaS, and analytics delivery through services such as mobile app development, React Native development, Flutter development, and SEO services.
Final Thoughts
Enterprise RAG can become one of the most practical ways to bring generative AI into regulated business environments. But it only works when the architecture is built for production, not just for demos.
The strongest systems retrieve the right evidence, respect permissions, cite sources, monitor quality, and improve continuously.
Planning an enterprise RAG rollout across the USA, UK, Germany, or EU? Mak It Solutions can help assess data readiness, design secure RAG architecture, evaluate vendors, and build production-ready AI workflows.
Book a scoped consultation with Mak It Solutions before scaling your enterprise RAG system across regulated markets.(Click Here’s )
Key Takeaways
Enterprise RAG works best when retrieval, governance, evaluation, observability, and compliance are designed together.
Hybrid search, graph RAG, agentic RAG, and corrective RAG solve different enterprise problems. The right pattern depends on your data, workflow, users, and risk level.
Most failures come from poor retrieval quality, stale data, weak permissions, and missing evaluation.
USA, UK, Germany, and EU deployments need different assumptions for HIPAA, SOC 2, PCI DSS, UK-GDPR, GDPR, DSGVO, BaFin, and EU AI Act readiness.
Before scaling, assess your data readiness, security model, compliance exposure, and ownership structure.
FAQs
Q : Is enterprise RAG better than fine-tuning for private company data?
A : Enterprise RAG is usually better when company knowledge changes often, users need citations, or permissions matter. Fine-tuning can help with tone, format, classification, or domain language, but it does not automatically keep answers current. Many enterprises use both.
Q : Which vector database features matter most for production RAG?
A : The most important features are hybrid search, metadata filtering, permission-aware retrieval, scalable indexing, high availability, reranking support, auditability, encryption, and cloud integration. For regulated workflows, role-based filtering is often more important than raw benchmark speed.
Q : How often should enterprise RAG indexes be refreshed?
A : Refresh frequency depends on risk and document change rate. Policies, pricing, incident records, clinical guidance, and financial rules may need frequent updates. Lower-risk knowledge bases can refresh less often, as long as ownership and expiry rules are clear.
Q : Who owns RAG governance in a large organization?
A : RAG governance is usually shared. Platform engineering owns infrastructure, data teams own source quality, security owns access controls, legal and compliance define risk requirements, and business owners approve answer quality.
Q : Can enterprise RAG work with SAP and SharePoint?
A : Yes. Enterprise RAG can work with SAP, SharePoint, CRMs, databases, file stores, ticketing tools, and legacy portals. The main challenge is preserving permissions, metadata, document structure, and business context while connecting those systems to secure retrieval workflows.