

SRE for Small Teams: A Practical Guide
Small teams do not need a full SRE department to improve reliability. They need a focused system: a few meaningful SLOs, better alerting, clear ownership, and an incident process the team can actually follow.
That is what SRE for small teams looks like in practice. For SaaS companies in the US, UK, Germany, and the wider EU, it is often the fastest way to reduce downtime, improve release confidence, and build a stronger operational foundation without adding unnecessary headcount.
A startup in Austin, a London scale-up selling into NHS-adjacent markets, or a Berlin SaaS company handling regulated customer data can all run into the same problems early: noisy alerts, unclear ownership, weak rollback plans, and too much firefighting. You do not need more chaos to justify SRE. You need recurring operational pain.
What SRE for Small Teams Really Means
SRE for small teams means applying reliability practices such as SLOs, observability, incident response, and automation without creating a large dedicated SRE org.
The goal is not simply to keep infrastructure alive. It is to make reliability measurable, repeatable, and tied to product and business decisions.
A simple definition for lean teams
In practical terms, SRE helps small engineering teams protect the user experience when capacity is limited.
That usually means starting with the services customers notice first, such as.
Sign-in and authentication
Checkout or payment completion
Core API performance
Billing events
Report generation
Main workflow completion
You do not need to instrument everything on day one. You need visibility into the parts of the product that hurt customers and revenue first.
How SRE differs from traditional ops and DevOps
Traditional ops often focuses on infrastructure upkeep.
DevOps usually improves collaboration, deployment flow, and delivery speed.
SRE adds a reliability policy layer. It answers questions like.
What does “good enough” reliability look like?
Which services matter most to users?
How much failure risk can we tolerate?
When should we pause feature work to stabilize a service?
That is why SRE works so well for lean SaaS teams. It gives engineering leaders and founders a shared framework instead of endless arguments about whether something is “stable enough.”
Why startups and SMEs need it earlier than they think
Small teams rarely struggle because people are not working hard enough.
They struggle because everyone is context switching. Alerts are noisy. Incident response depends on memory. Ownership is fuzzy. The same operational issues show up again and again.
In practice, reliability work creates leverage early. A cleaner alert strategy, one or two service-level objectives, and a few runbooks can save more engineering time than another sprint full of reactive fixes.
The Core SRE Foundations Small Teams Should Start With
You do not need an enterprise-sized platform team to begin. Most companies can start with a small set of high-impact practices.
Define a few SLIs and SLOs
Start with 2 to 3 user-visible indicators for your most critical workflows.
Examples.
API request success rate
Login availability
Payment completion rate
p95 latency for a core endpoint
Report generation time
Then set one realistic SLO for each important path. Keep it simple. The point is not to look impressive. The point is to create an operating standard the team can actually use.
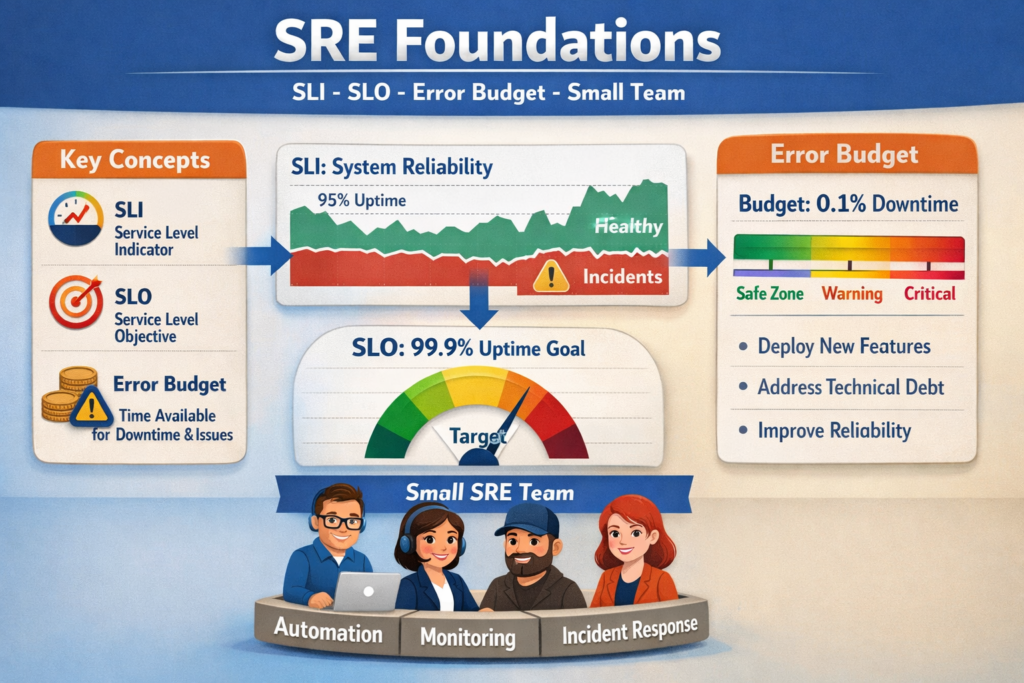
Create one basic error budget policy
An error budget helps teams decide when to keep shipping and when to slow down to improve stability.
For small teams, this matters a lot. Without a policy, reliability usually loses to roadmap pressure.
A lightweight policy might say.
If the service stays within SLO, feature delivery continues as planned
If error budget burn increases sharply, releases need closer review
If the budget is exhausted, stability work takes priority until the service recovers
That kind of rule removes emotion from the decision.
Prioritize critical services first
One of the biggest mistakes small teams make is trying to “do observability everywhere” all at once.
A better approach is to rank systems by business risk. Start with.
Revenue-generating workflows
Customer-facing paths
Authentication and access flows
Compliance-sensitive systems
Core APIs and service dependencies
This keeps the work manageable and gives leadership a clear reason for every reliability investment.
Make ownership explicit
Reliability improves faster when ownership is clear.
For each critical service, define.
An engineering owner
A product or business stakeholder
An operational escalation path
In small teams, clear ownership usually matters more than perfect tooling.
Monitoring, Incident Response, and Toil Reduction Without More Headcount
Better reliability is not only about staffing. It is about visibility, response speed, and reducing repetitive work.
A lean observability stack with strong ownership often performs better than a bloated toolset that nobody maintains properly.
What observability small SaaS teams actually need
Most small SaaS companies do well with four basics.
Application metrics
Centralized logs
Tracing for core workflows
Alert routing tied to service ownership
That setup can be built with open tools, managed services, or a hybrid approach. The exact stack matters less than whether the team actually uses it consistently.
A good baseline dashboard should show.
Error rate
Latency
Dependency health
Deployment events
Queue backlog or processing delay
Active incidents or alert status
Alerting rules that reduce noise
More alerts do not create better reliability. Better alerts do.
Good alerting focuses on user impact and sustained failure, not every temporary spike. A US healthcare SaaS company may care more about failed login bursts and audit-path failures than raw CPU noise. A London fintech team may care more about payment latency and failed confirmations. A Germany-based B2B platform may need stronger visibility into region-aware services and dependency chains because buyer expectations around governance and auditability are often higher.
Useful alerting rules usually have these traits.
They map to a real service owner
They reflect customer impact
They are actionable
They avoid duplicate noise
They include severity levels
They support faster triage
Cut toil before you add tools
Toil reduction is where small teams often see quick wins.
Start by automating repetitive operational work such as.
Restart procedures
Rollback scripts
Cache-clear routines
Dependency health checks
Incident templates
Common remediation steps
Post-incident follow-up checklists
From a small business point of view, these changes matter because they reduce interruption cost. Every manual repeat task steals time from roadmap work, customer support, and product quality.

SLO Examples and Reliability KPIs for SaaS Teams
Without SLOs and shared reliability metrics, every uptime discussion becomes subjective.
That usually ends the same way: feature pressure wins, operational debt grows, and incidents become more expensive.
Practical SLO examples for small teams
Here is a realistic starting point for many SaaS products.
| Service or Workflow | Example Target |
|---|---|
| SaaS app login success | 99.9% |
| Core API success rate | 99.95% |
| Checkout or payment completion | 99.9% |
| Customer-facing report generation under 10 seconds | 99% |
These are starting points, not universal rules.
A startup in San Francisco may be comfortable beginning here. A compliance-heavy workflow in Frankfurt or Dublin may need stricter latency expectations, stronger audit trails, and tighter recovery standards.
The KPIs that matter most
For most small teams, the most useful reliability KPIs are.
Uptime
MTTR
Change failure rate
Alert quality
Deployment-related incident volume
Error budget burn
These metrics give a fuller picture than uptime alone. A service can look “available” on paper while still causing real customer frustration through slow response times, brittle releases, or recurring degraded states.
Set targets based on customer promise
Your targets should reflect what customers expect and what your market demands.
A lightweight internal workflow tool may tolerate more variance. A SaaS product operating in healthcare, fintech, payments, or regulated B2B procurement usually cannot.
That is especially true for teams selling into the US, UK, and EU, where buyers often expect stronger evidence around recoverability, logging, incident handling, and operational maturity.
Compliance and Regional Reliability Priorities in the US, UK, Germany, and EU
Reliability standards are not shaped by engineering preferences alone. In regulated environments, they are also shaped by customer scrutiny, procurement requirements, and compliance obligations.
For small teams, this changes priorities quickly.
US priorities
In the US, teams working in healthcare, payments, and security-sensitive SaaS environments often need stronger controls around.
Access management
Logging and audit evidence
Incident response
Recoverability
Change discipline
HIPAA-facing teams, PCI DSS-related workflows, and SOC 2-conscious buyers all push reliability conversations beyond “Is the app up?” and into “Can you prove your controls work under pressure?”
UK priorities
In the UK, reliability often intersects with UK GDPR expectations, ICO guidance, and sector-specific buyer reviews.
This becomes more visible when selling into public-sector-adjacent or healthcare-related environments. Teams working with NHS-linked buyers, for example, may need cleaner operational evidence, stronger documentation, and more mature incident readiness than early-stage founders initially expect.
Germany and wider EU priorities
In Germany and across the wider EU, small SaaS teams often run into reliability questions through the lens of governance, outsourcing, data handling, and resilience.
That is especially relevant in regulated sectors. Teams serving finance-related buyers, enterprise procurement groups, or compliance-heavy customers may need to think earlier about.
Data residency
Region-aware deployment
Supplier oversight
Incident readiness
Operational resilience testing
Many teams in Berlin, Munich, Amsterdam, and Dublin notice this shift as soon as they move upmarket.
When SRE as a Service Makes More Sense Than Building In-House
Not every company should build a full internal SRE function early.
Sometimes the smarter option is fractional or managed support.
This is often the better fit when the business is growing faster than the engineering org can formalize operations.

Signs you may need outside help
You likely need external support when.
Incidents repeat without meaningful follow-through
Nobody clearly owns SLOs
Alerts wake people up without giving them anything useful to do
Postmortems do not lead to change
Buyers ask for resilience evidence the team cannot provide cleanly
Engineers are stuck in operational firefighting
What a good SRE partner should help with
A strong partner should be able to support.
Service mapping
SLI and SLO design
Alert tuning
Incident workflow design
Runbook creation
Toil automation
Cloud-region and architecture decisions
Reliability reviews tied to business priorities
For teams that already have solid developers but weak operational structure, outside help can accelerate maturity without committing to permanent headcount too early.
What to look for in the US, UK, and Europe
Regional context matters.
A partner that understands SaaS uptime in general is useful. A partner that also understands HIPAA-adjacent controls, UK GDPR pressure, GDPR and DSGVO expectations, PCI DSS realities, and regulated outsourcing concerns is usually much more valuable.
That matters even more when your cloud footprint spans locations such as London, Frankfurt, or other region-sensitive environments where architecture choices can affect both performance and buyer confidence.
A 90-Day SRE Rollout Plan for Small Engineering Teams
The easiest way to implement SRE for small teams is to keep the rollout phased and realistic.
Days 1 to 30: visibility, ownership, and baselines
Focus first on understanding how the system behaves.
Actions for this phase
Map the top 3 customer journeys
Assign owners for each critical service
Build dashboards for errors, latency, dependencies, and deployments
Document where incidents usually begin
Identify where response slows down
Do not overcomplicate this stage. The goal is visibility.
Days 31 to 60: SLOs, alert cleanup, and incident process
Now add control.
During this phase.
Define 1 to 2 SLOs for each critical workflow
Remove noisy or low-value alerts
Add a simple severity model
Create an escalation path
Write short runbooks for common issues
At this point, the team should start feeling less reactive.
Days 61 to 90: automation and fit check
Use the final phase to remove repetitive work and review what the team has learned.
Priorities here.
Automate the most repetitive ops tasks
Review error budget burn
Identify services that remain fragile
Decide what stays internal
Decide whether fractional SRE support would accelerate progress
This gives leadership a clearer answer than guessing whether “we need SRE now.”

Final Thoughts
If your team is shipping quickly but handling reliability one incident at a time, now is the right moment to tighten the system.
SRE for small teams works because it turns reliability from a vague concern into a practical operating model. You do not need a massive platform org to get there. You need a few clear service targets, better operational habits, and the discipline to fix the repeated pain points first.
For teams that want a practical roadmap, this is also a natural place to connect reliability work with broader delivery decisions through Business intelligence services or Contact page.
Key Takeaways
SRE for small teams is not about copying large tech companies
It is about choosing a few reliability practices that create the most leverage
Start with customer-visible services and critical workflows
Clear ownership, cleaner alerts, and a simple incident process usually create fast wins
Compliance-heavy markets in the US, UK, Germany, and the wider EU raise the importance of auditability, recoverability, and operational discipline
Managed or fractional SRE support makes sense when uptime risk grows faster than internal capacity
FAQs
Q : How many services should a small team put under SLOs first?
A : Start with 1 to 3 services. Choose the workflows customers notice immediately, such as login, payments, or the main API path. Keeping the first scope small makes the process easier to manage and review.
Q : What is a realistic uptime target for an early-stage SaaS product?
A : Many early-stage products begin around 99.9% for critical customer-facing workflows. Over time, teams usually tighten targets as monitoring, architecture, and support maturity improve.
Q : Can DevOps engineers handle SRE responsibilities in a startup?
A : Yes. In many startups, DevOps engineers, senior backend engineers, or platform-minded engineering managers can own early SRE responsibilities. What matters most is clear ownership, not the exact title.
Q : Which observability tools are best for compliance-focused SaaS teams in Europe?
A : Usually, the best stack is the one your team can maintain well. For UK and EU teams, audit trails, access controls, retention policies, and region-aware deployment often matter more than chasing every new tool.
Q : How do you know when to move from internal reliability work to managed SRE services?
A : That shift usually makes sense when recurring incidents, noisy alerts, weak postmortems, or buyer scrutiny are growing faster than your team can handle. When operational risk starts slowing product progress, outside support can become the more efficient option.
[…] in practical […]